Bi-AQUA: Bilateral Control-Based Imitation Learning for Underwater Robot Arms via Lighting-Aware Action Chunking with Transformers
The University of Osaka / Kobe University
- Takeru Tsunoori (Master’s student, 1st year) is primarily responsible for 3D printed hardware development, data preprocessing software, and experimental execution.
- Masato Kobayashi (Assistant Professor, project tech lead) is primarily responsible for robot learning model construction, computer vision and robot control software, website, and video editing.




Contributions
Our contributions are as follows:
- Bi-AQUA is the first bilateral control–based imitation learning framework for underwater robot arms.
- We propose a lighting-aware visuomotor policy that integrates a label-free, implicitly supervised Lighting Encoder, FiLM modulation, and a lighting token for adaptive control.
- We demonstrated real-world gains over baseline and generalization to unseen lighting conditions, novel objects, and visual disturbances in underwater environments.
Multi-stage drawer closing task requiring sustained contact-rich force interaction.
Short Video: Dynamic Changing Drawer Task via Bi-AQUA.
Motivation and Related Work
Challenges in Underwater Manipulation
Underwater robotic manipulation is uniquely challenging because the visual appearance of the same scene can change drastically within seconds under shifts in the spectrum, intensity, and direction of underwater lighting. Such variations—caused by wavelength-dependent attenuation, scattering, turbidity, and bubbles—break the visual consistency required by standard visuomotor policies, often causing catastrophic action drift even on simple pick-and-place tasks. Existing underwater image enhancement methods improve image quality, but they do not address the fundamental control problem: closed-loop manipulation policies must adapt both perception and action generation to rapidly varying lighting.
Traditional underwater manipulation is dominated by teleoperation, motivating recent work on AUVs, underwater robot arms, and visuomotor learning. However, existing approaches either rely solely on vision or use unilateral control without force feedback, and none provide mechanisms to explicitly model lighting as a latent factor influencing visual observations.
Research Gaps and Our Approach
To clarify why Bi-AQUA uniquely addresses the challenges of underwater manipulation, we compare representative approaches across five key dimensions: RGB vision, underwater deployment, bilateral control, robot policy learning, and explicit lighting modeling. The following analysis reveals critical gaps that motivate our approach. Bi-AQUA is the first Bi-IL framework explicitly designed for real underwater manipulation under dynamic lighting, bridging the gap between bilateral control-based imitation learning and underwater manipulation.
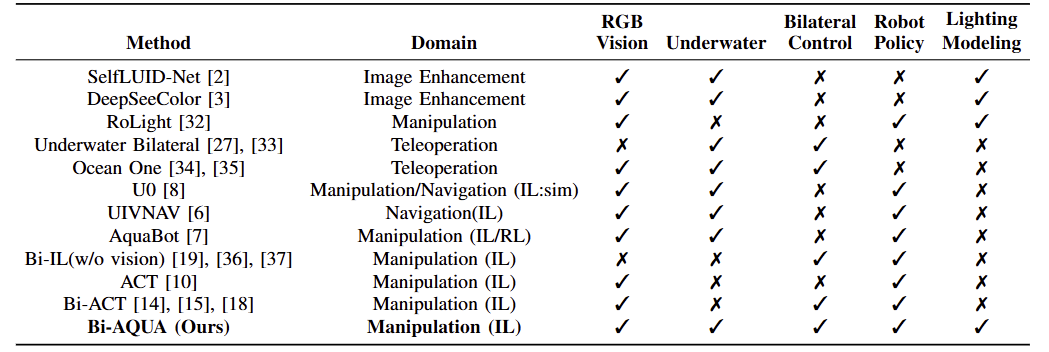
Why Underwater?
Existing underwater manipulation approaches fall into three categories, each with critical limitations:
Image Enhancement Methods (SelfLUID-Net, DeepSeeColor): These methods improve underwater image quality and model lighting, but they operate at the image level and do not address closed-loop control. They lack robot policy learning and cannot adapt action generation to lighting changes during manipulation.
Underwater Teleoperation Systems (Underwater Bilateral, Ocean One): While these systems support bilateral control and underwater deployment, they remain human-operated and do not learn autonomous policies. They also lack explicit lighting modeling, relying on human operators to compensate for visual degradation.
Underwater Imitation Learning (U0, UIVNAV, AquaBot): These methods learn robot policies for underwater tasks but use unilateral control without force feedback. This limits their robustness in contact-rich manipulation, where haptic cues are essential. Critically, none of these approaches explicitly model lighting as a latent factor, leaving them vulnerable to the rapid appearance shifts characteristic of underwater environments.
Gap: No existing method combines underwater deployment, autonomous policy learning, and explicit lighting modeling. Bi-AQUA is the first to unify these capabilities.
Why Bilateral Control-Based Imitation Learning?
In terrestrial environments, imitation learning (IL) through leader–follower teleoperation has proven highly effective for acquiring complex visuomotor skills. Recent systems based on ALOHA and Action Chunking with Transformers (ACT), Mobile ALOHA with ACT, and diffusion-based visuomotor policies achieve impressive real-world performance. However, these methods all rely on unilateral control, as shown below. Without force feedback, these methods struggle in contact-rich or visually ambiguous interactions.
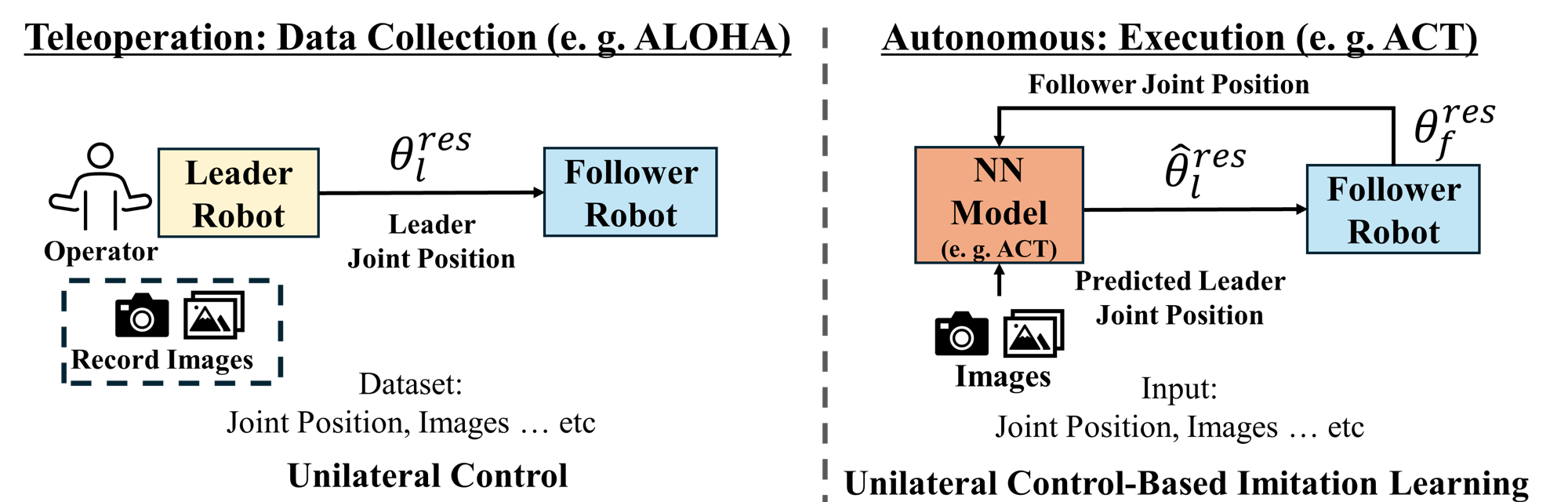
Unilateral Control-based Imitation Learning
Bilateral control addresses this limitation by exchanging both position and force, enabling demonstrations rich in haptic and visual cues and yielding more robust generalization, as shown below. Among bilateral IL frameworks, Bi-ACT plays a central role by directly extending ACT to bilateral settings, offering a strong backbone for force-sensitive visuomotor learning. However, all such work assumes visually stable land environments and does not address the severe lighting variability characteristic of underwater settings.
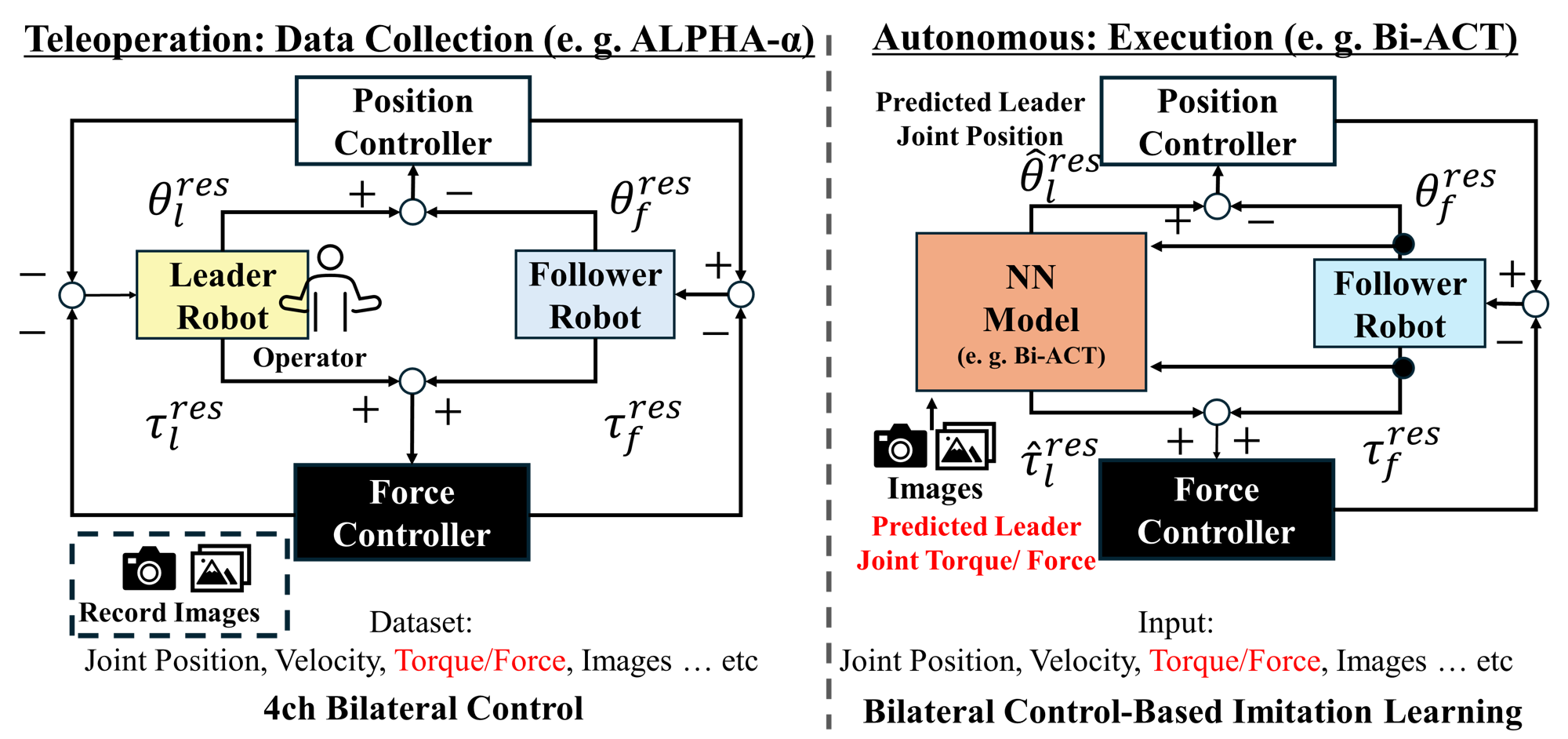
Bilateral Control-based Imitation Learning
Bilateral control-based imitation learning (Bi-IL) offers significant advantages over unilateral approaches, but existing Bi-IL frameworks have critical limitations:
- Vision-Free Bi-IL (Bi-IL without vision): These methods leverage bilateral control for force-sensitive learning but operate without visual input, making them perceptually blind. This is particularly problematic in underwater environments, where visual feedback is essential for object localization and manipulation planning.
- Terrestrial Bi-IL (Bi-ACT): Bi-ACT successfully combines bilateral control with RGB vision for terrestrial manipulation, demonstrating the power of force-rich demonstrations with high-dimensional perception. However, it assumes visually stable land environments and has not been evaluated underwater, where lighting variability fundamentally breaks visual consistency.
Gap: Existing Bi-IL frameworks either lack vision (limiting underwater applicability) or assume stable lighting (incompatible with underwater conditions). Bi-AQUA extends Bi-IL to underwater settings while explicitly modeling lighting variability.
Why Lighting Modeling?
Lighting variability is a dominant factor degrading visuomotor policy performance, especially in underwater environments. Existing approaches to lighting robustness have fundamental limitations:
Domain Randomization and Data Augmentation: Prior work improves robustness through domain randomization and physically based relighting for data augmentation. While effective for training, these strategies do not provide the policy with an explicit, internal representation of lighting. The visuomotor pipeline must implicitly cope with color and illumination changes, which is insufficient for rapid, intra-horizon lighting shifts in underwater settings.
Implicit Lighting Conditioning: Some methods (e.g., RoLight) model lighting for terrestrial manipulation, but they treat lighting only implicitly through global conditioning or augmentation, without identifying lighting as a distinct latent factor that affects both perception and downstream control.
Image Enhancement Without Control Integration: Underwater image enhancement methods (SelfLUID-Net, DeepSeeColor) explicitly model lighting to improve image quality, but they operate independently of the control loop. They do not enable the policy to adapt action generation to current lighting conditions.
Gap: No existing method provides explicit, hierarchical lighting modeling within a visuomotor policy for underwater manipulation. Bi-AQUA introduces a label-free Lighting Encoder that learns lighting representations implicitly through the imitation objective, modulates visual features via FiLM, and conditions action generation through a lighting token—enabling adaptation to rapidly changing underwater illumination.
Summary: Bi-AQUA is the first framework to simultaneously address all three gaps: (i) underwater deployment with autonomous policy learning and explicit lighting modeling, (ii) bilateral control-based imitation learning with vision for underwater manipulation, and (iii) hierarchical lighting modeling that adapts both perception and control to dynamic underwater illumination.
Bi-AQUA Model
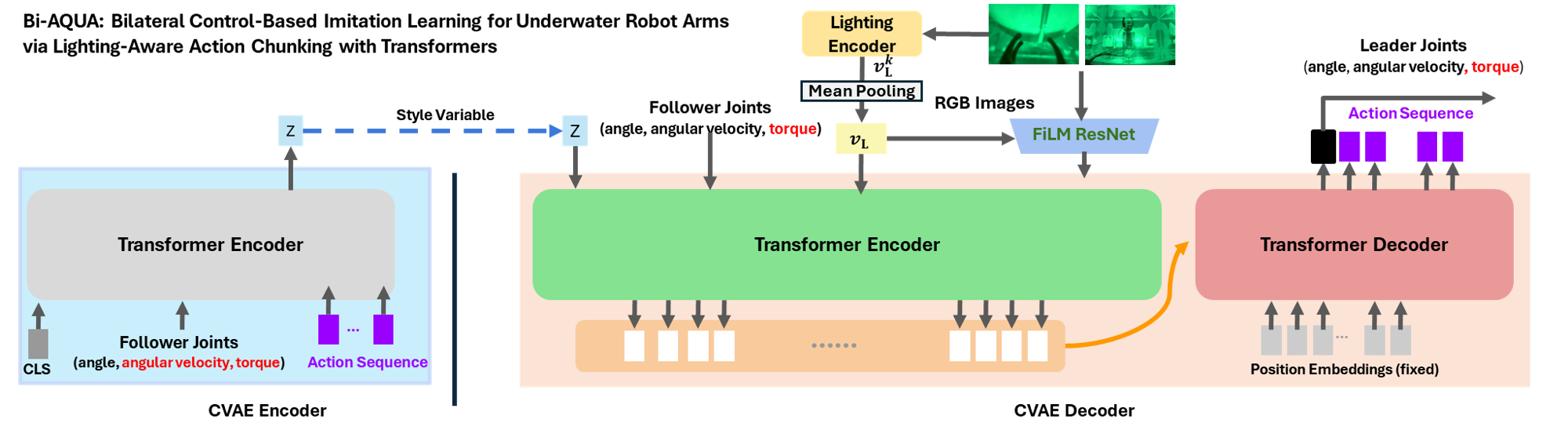
Bi-AQUA Model
- a label-free lighting-aware visual encoder,
- a joint state encoder,
- a transformer-based action prediction module,
- bilateral control integration for closed-loop execution.
Bi-AQUA employs a hierarchical three-level lighting adaptation mechanism:
- Lighting Encoder: Extracts compact lighting embeddings from RGB images without manual annotation, implicitly supervised by the imitation objective
- FiLM-based feature-wise modulation: Modulates backbone features conditioned on the lighting embedding for adaptive, lighting-aware feature extraction. Following the formulation of FiLM, we modulate each convolutional feature map via a feature-wise affine transformation whose parameters are generated from the lighting embedding. In our implementation, FiLM is applied to the final ResNet layer.
- Lighting token: Added to the transformer encoder input alongside latent and proprioceptive tokens. The encoder processes these tokens together, and the resulting memory (which includes the lighting information) is then accessed by the transformer decoder via cross-attention, enabling the decoder to adapt action generation to the current underwater lighting.
Lighting Encoder
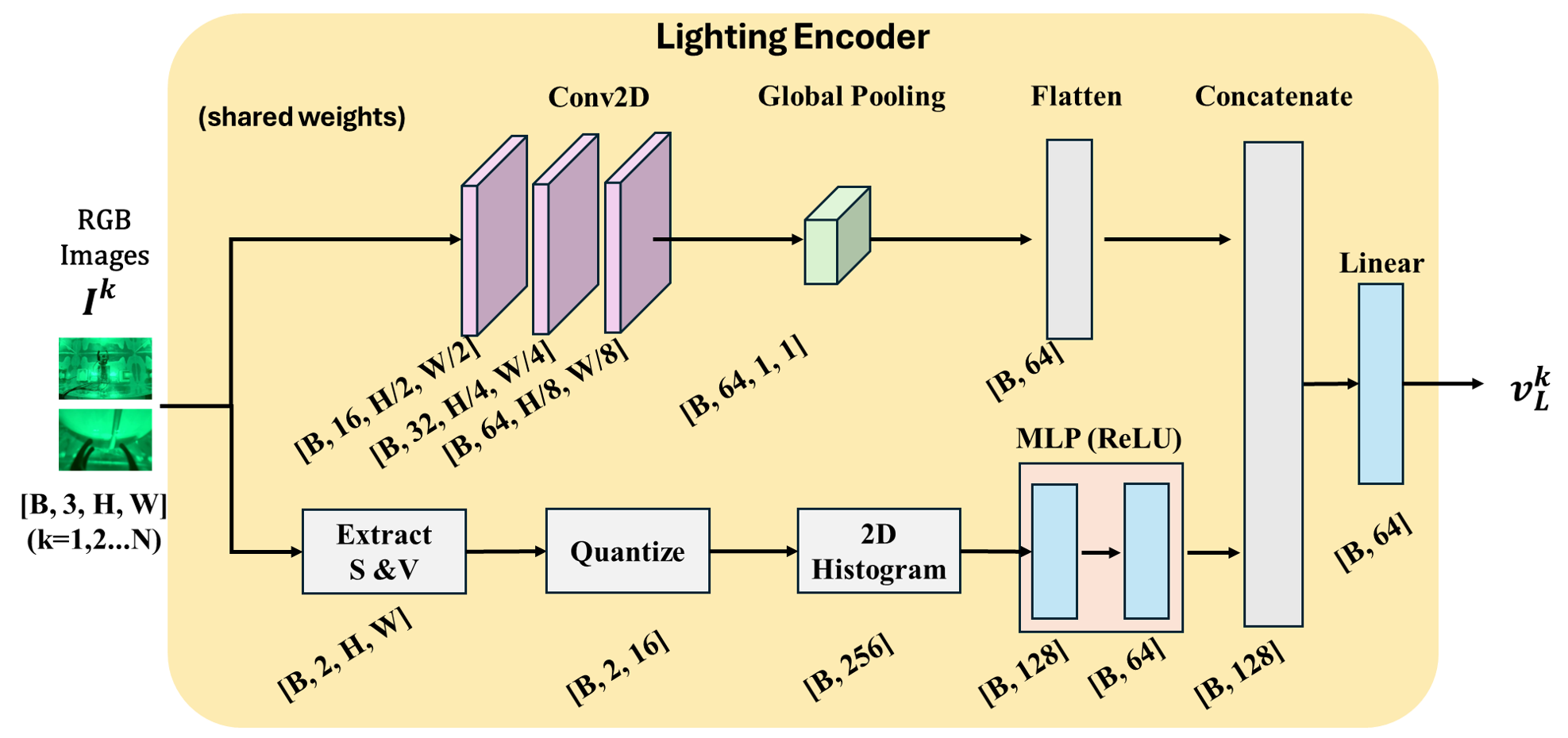
Lighting Encoder
The encoder adopts a dual-path architecture. A convolutional path processes the input through convolutional layers with channels 3 → C₁ → C₂ → C₃, followed by ReLU and global average pooling to yield spatial features. A histogram path computes a 2D histogram over saturation and value (SV) channels and passes it through a two-layer MLP. The final lighting embedding is obtained by concatenating and linearly projecting the features from both paths. For multiple cameras, we use a shared encoder and average across views.
Data Collection: Bilateral Control for Underwater Manipulation
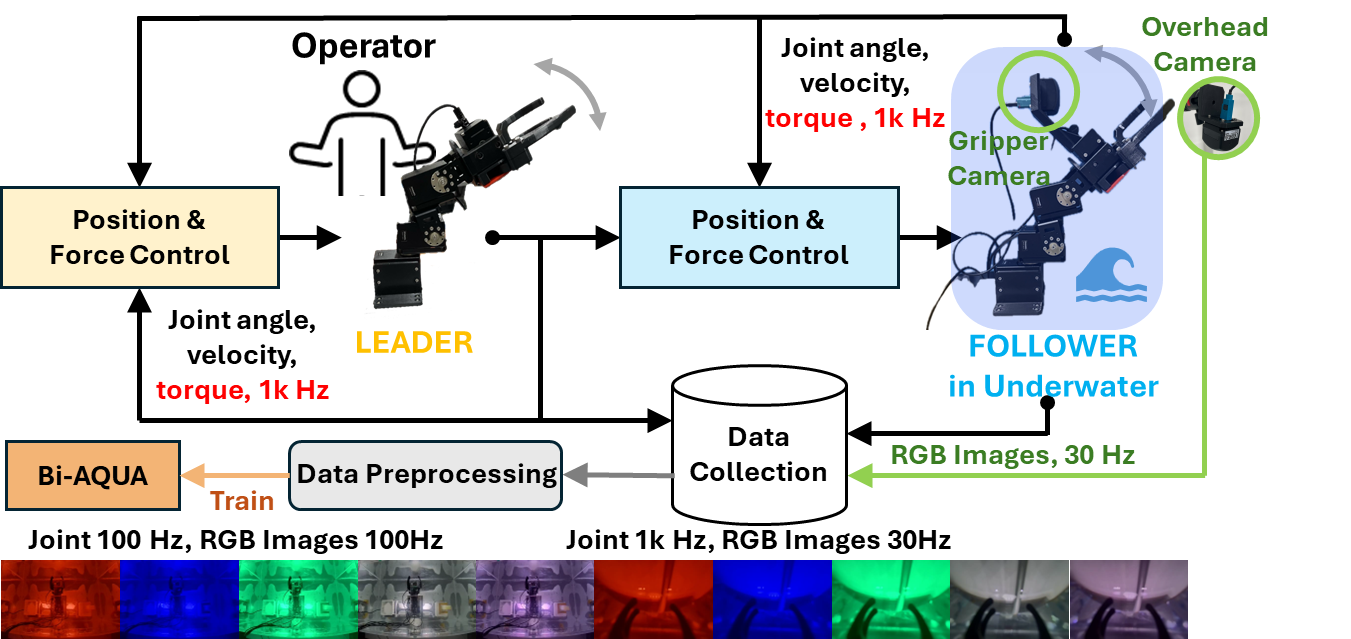
Bi-AQUA Data Collection
Inference
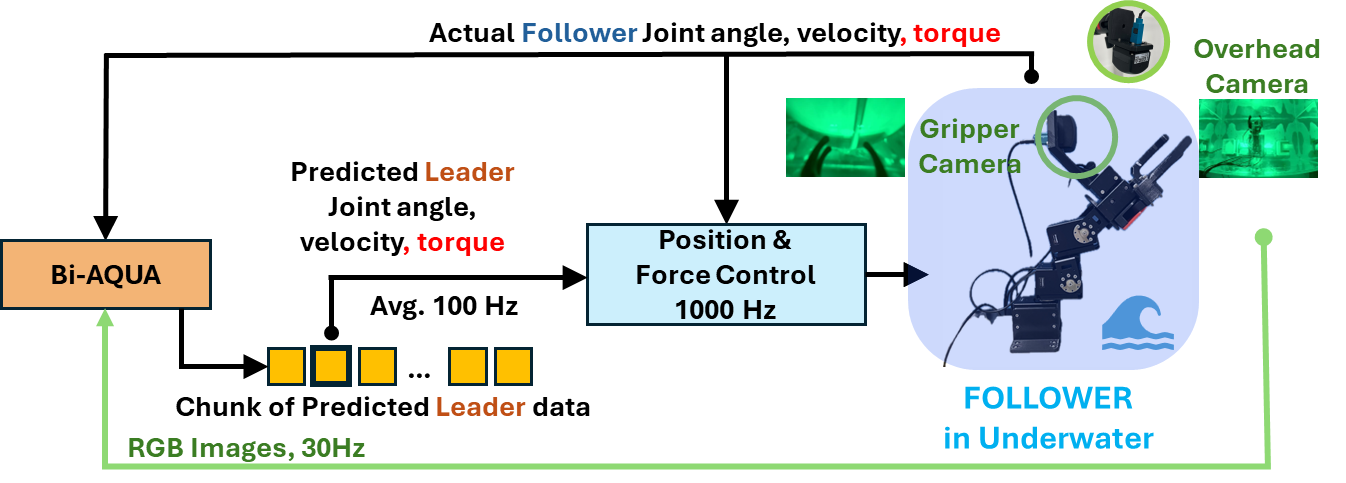
Bi-AQUA Inference
Experiments
Overview
We evaluate Bi-AQUA on a real-world bilateral leader–follower system in an underwater tank. A human operator provides demonstrations via a leader robot in air; the policy is executed on a follower robot underwater, trained from those demonstrations under bilateral control.
Across all tasks, we use a unified train/test lighting protocol to isolate the effect of lighting variation. We collect bilateral teleoperation demonstrations under five training lighting modes (red, blue, green, white, rgbw) and evaluate under all eight modes, including two unseen colors (cyan, purple) and a dynamic changing condition where the light cycles every 2 seconds. Unless otherwise noted, each test configuration is evaluated over 5 autonomous rollouts and we report task success rate.
We consider three manipulation tasks with progressively increasing temporal horizon and contact complexity:
- Pick-and-Place Task: a lighting-robustness benchmark in which the robot transports an object across the tank.
- Drawer Closing Task: a long-horizon sequential task with an additional drawer-closing operation.
- Peg Extraction Task: a contact-rich precision manipulation task requiring stable grasping and controlled disengagement.
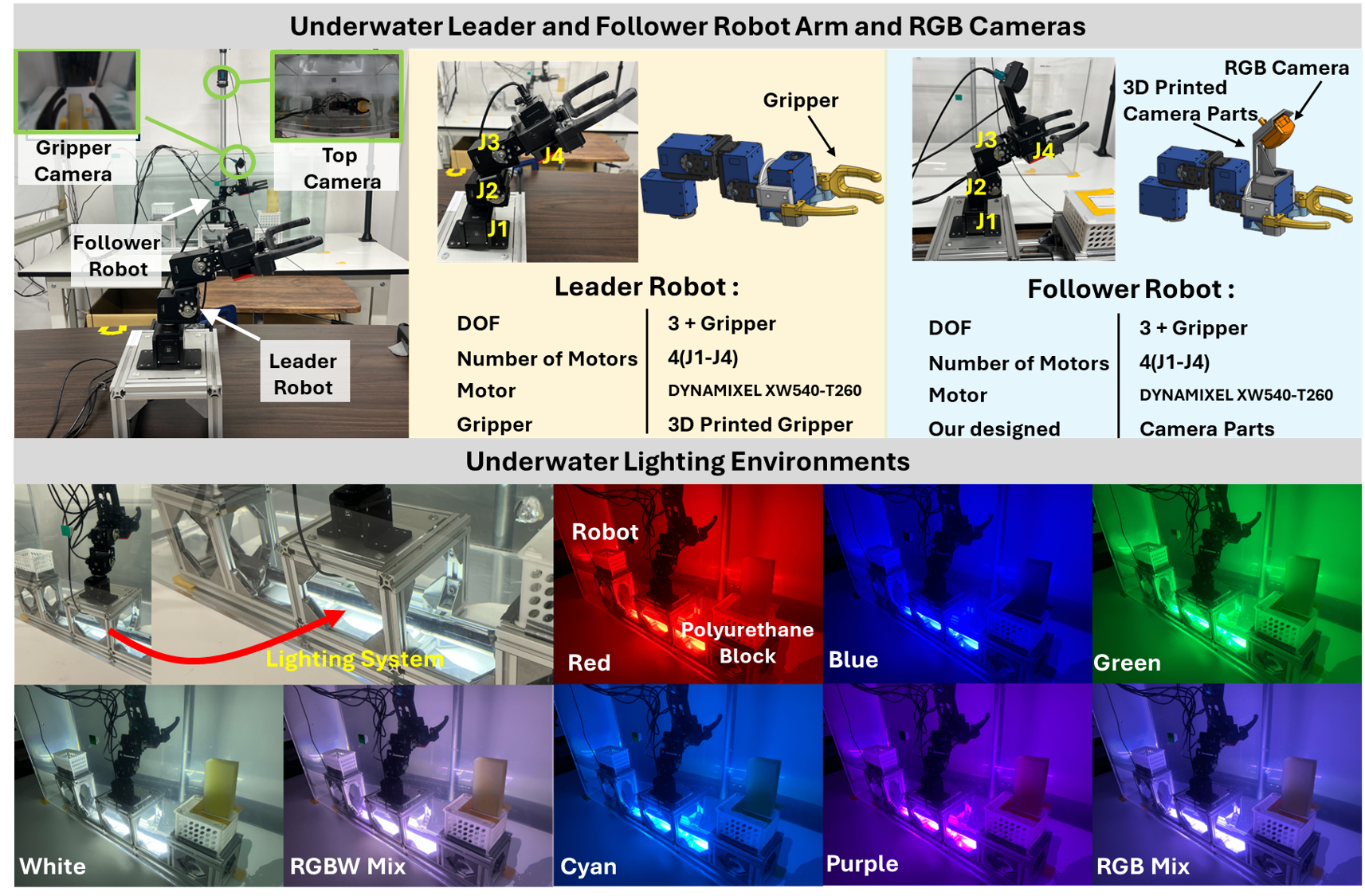
Experimental Environments
Hardware Setup
- Robot: Dynamixel XW540-T260 (IP68) servo motors, 3 joints (J1-J3) + gripper (J4)
- Water Tank: 900 × 450 × 450 mm, follower arm mounted on 200 mm pedestal
- Lighting: Multi-color RGBW LED aquarium light (FEDOUR RD10-400RGBW) providing eight reproducible lighting conditions (red, blue, green, white, rgbw, cyan, purple, changing)
- Cameras: Two RGB cameras (TIER IV C1 120) - gripper-mounted camera for close-up views and top camera capturing the global workspace
- Bilateral control: Leader–follower, four-channel (position/force exchange)
Pick-and-Place Task
The pick-and-place task is designed to directly stress lighting robustness in underwater manipulation. The follower must grasp a polyurethane block on the right side of the tank and place it into a basket on the opposite side, passing through four stages: (1) initial pose, (2) pick up, (3) transport, (4) place. A rollout is considered successful if the object ends inside the basket without being dropped.
To test robustness beyond the training object and scene, we additionally evaluate: (a) a black rubber block, (b) a blue sponge, and (c) bubbles around the polyurethane block. These settings are evaluated under the same eight lighting modes with the same success criterion.

Teleoperation Data Collection

Generalization to Novel Objects and Disturbances
Training Setup
- Sensing/Logging: 1000 Hz joint angle/velocity/torque for both leader and follower (4 joints × 3 = 12 per arm; 24-D combined). RGB images at 30 Hz (1920 × 1280), resized to 480 × 320.
- Demonstrations: 10 bilateral teleoperation episodes (two per training lighting condition). All demonstrations execute the same pick-and-place task; the operator follows an identical intended motion pattern across episodes so that the primary variation comes from lighting rather than from changes in the manipulation strategy.
- Preprocessing: Joint data downsampled to 100 Hz, images temporally aligned to 100 Hz by selecting the frame closest to each 10 ms interval. This results in 15,402 time steps, corresponding to 30,804 RGB frames in total (two views per time step) and 15,402 synchronized joint-state vectors; each contains 24 values (leader+follower, 4 joints × position/velocity/torque), totaling 369,648 values.
- Note: Although each episode is collected under a known lighting mode (e.g., red, blue, green), we do not provide any lighting IDs or manual labels to the policy. The Lighting Encoder is trained end-to-end from the control objective and learns a latent representation of lighting purely from visual input.
- Training: CVAE-style action chunks with KL regularization (λ_KL = 1.0), using AdamW optimizer for both the ResNet-18 backbone and the remaining modules
- Deployment: Trained policies run in real time on the physical robot using an NVIDIA RTX 3060 Ti GPU (8 GB VRAM)
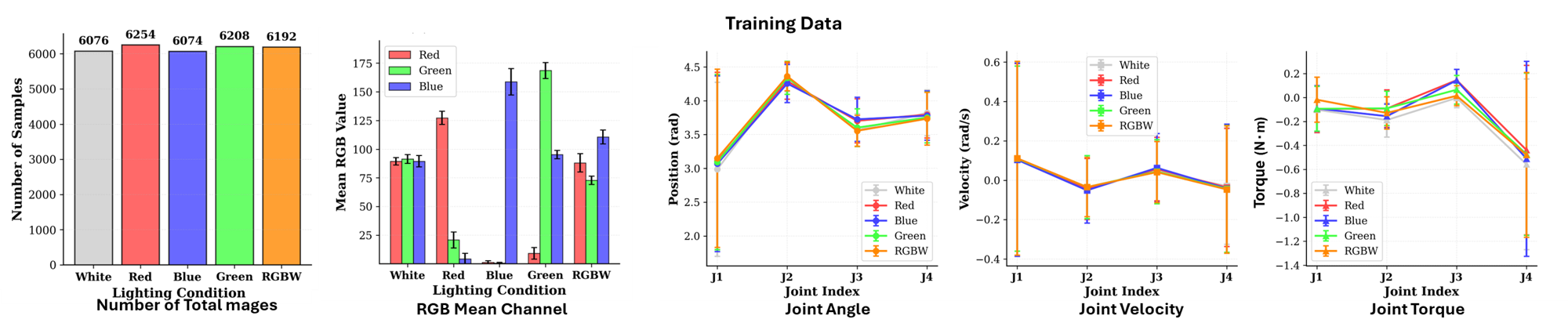
Overview of Collected Datasets
Results
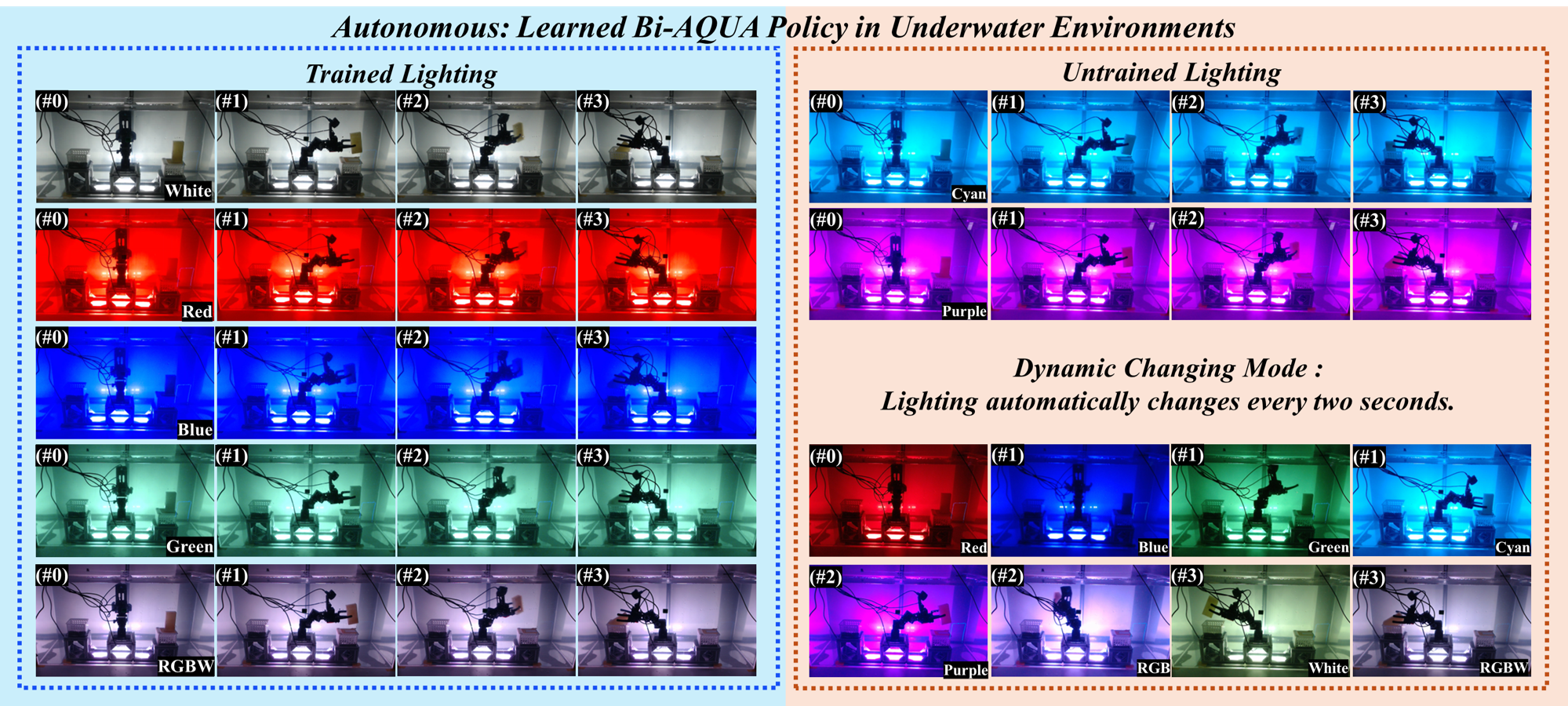
Autonomous Execution of Bi-AQUA
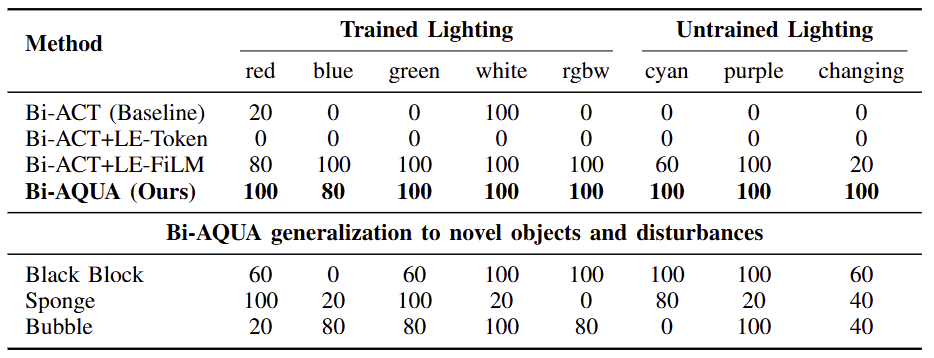
Results of Bi-AQUA
Key Findings:
- Bi-AQUA achieves consistently high robustness, attaining 100% success in seven of the eight lighting conditions and maintaining 80% success even under blue light, which is the most challenging condition due to severe wavelength-dependent attenuation.
- Crucially, Bi-AQUA achieves 100% and clearly outperforms all baselines in the dynamic changing mode, where lighting cycles through all spectra every 2 sec. This setting induces rapid, intra-horizon appearance shifts that invalidate the stationarity assumptions of standard visuomotor policies.
- The lighting-agnostic Bi-ACT baseline succeeds only under white (100%) and partially under red (20%), and fails completely in the remaining six conditions despite using the same demonstrations. This sharp performance gap demonstrates that underwater visuomotor control fundamentally requires explicit lighting modeling rather than relying on passive robustness of the visual backbone.
Ablation Studies:
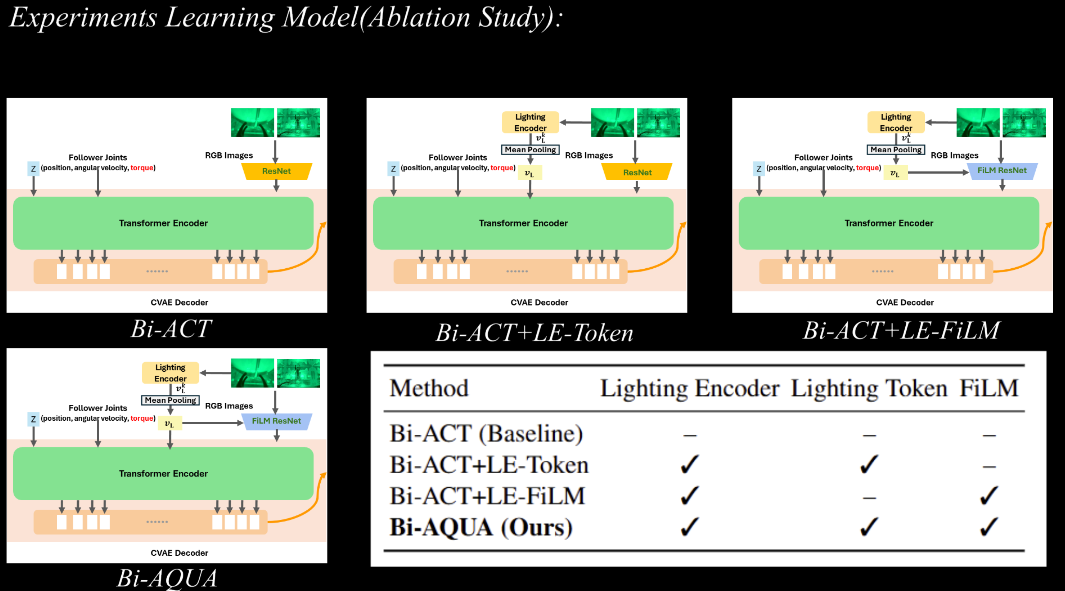
Ablation Studies
The ablations isolate the role of each lighting-aware component:
- Bi-ACT+LE-Token, which uses a Lighting Encoder to extract lighting embeddings and adds a lighting token to the transformer encoder input (conditioning the decoder via memory) without modifying the visual features via FiLM, fails in all lighting conditions. This indicates that high-level conditioning alone is insufficient for correcting color shifts and contrast changes introduced by underwater propagation.
- Bi-ACT+LE-FiLM, which uses a Lighting Encoder to extract lighting embeddings and applies FiLM modulation to the final ResNet layer (layer4) but omits the lighting token, performs substantially better, achieving up to 100% success in five static or unseen lighting conditions. However, its success drops sharply to 20% in the dynamic changing mode, suggesting that FiLM alone cannot track rapid temporal lighting transitions.
- Only the full Bi-AQUA model—combining Lighting Encoder, FiLM modulation, and a sequence-level lighting token—maintains uniformly high performance across all lighting conditions. This confirms that hierarchical lighting reasoning, spanning both feature modulation and sequence-level conditioning, is essential for underwater manipulation under severe lighting variability.
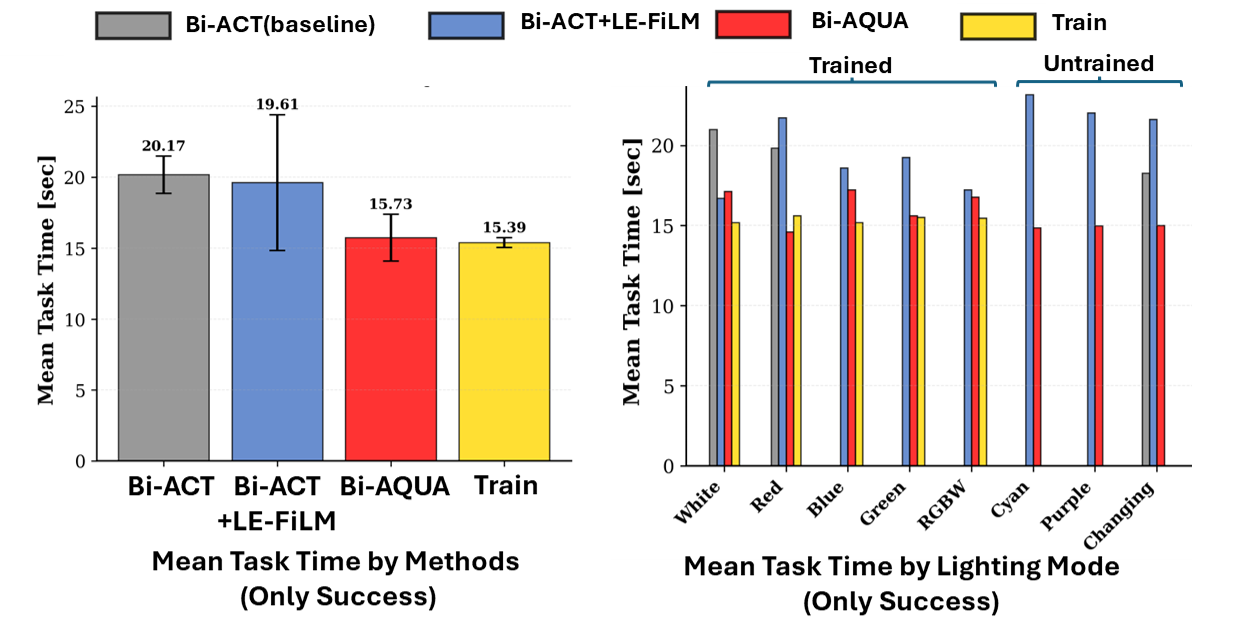
Execution Time Profiles
Averaged over all lighting conditions, Bi-ACT takes 20.17 sec per successful rollout, Bi-ACT+LE-FiLM 19.61 sec, Bi-AQUA 15.73 sec, and human teleoperation 15.39 sec. Bi-AQUA closely matches the teleoperation reference in both mean time and variance, suggesting that explicit lighting modeling not only increases success rates but also preserves efficient, human-like trajectories.
Generalization Analysis:
- For the black block, Bi-AQUA achieves success rates between 60% and 100%, with perfect performance under white, rgbw, cyan, and purple lighting. This indicates robustness to drastic changes in albedo and object contrast.
- For the blue sponge, which introduces significant geometric, textural, and chromatic variation, performance varies more widely (0–100%). Even under these severe appearance shifts, Bi-AQUA maintains non-trivial success rates across multiple lighting modes, achieving 80% under cyan and 40% in the dynamic changing mode.
- The bubble condition is particularly challenging from a perception standpoint. Because the top camera observes the scene through the water surface from above, air injection generates surface waves that induce strong refraction and temporal warping, severely degrading the global view of the tank. At the same time, bubbles rise around the gripper and the object, intermittently occluding the local workspace and creating high-frequency specular highlights and false edges in the gripper view. Despite these compounded distortions, Bi-AQUA still achieves up to 100% success in several lighting conditions, indicating substantial resilience to simultaneous global (water-surface) and local (near-gripper) disturbances.
Overall, these results show that Bi-AQUA not only provides strong lighting robustness but also extends to unseen objects and disturbance conditions without any additional data or fine-tuning.
Multi-stage drawer closing task requiring sustained contact-rich force interaction.
In the multi-stage drawer closing task, Bi-AQUA extends the pick-and-place sequence by appending a drawer-closing operation after placing the object into the target container. The robot must approach the drawer and perform a closing contact-rich motion; we define full-task success if both (i) the object is placed in the target container and (ii) the drawer reaches the closed state.
Bi-AQUA consistently outperforms a force-ablated variant across both seen and unseen lighting conditions. Under trained lighting modes, the full model achieves success rates of 100% in red, blue, and green illumination, and 80% in white and rgbw. Under untrained lighting, Bi-AQUA maintains high robustness with 100% success in cyan and 80% in purple and changing illumination, whereas the force-ablated policy shows inconsistent behavior. These results indicate that force integration significantly improves stability in long-horizon sequential manipulation, where perception drift and contact errors may accumulate over multiple stages.
Bi-AQUA
Short Video: Drawer Task via Bi-AQUA.Short Video: Dynamic Changing Drawer Task via Bi-AQUA.Without Force:
Short Video: Drawer Task via Bi-AQUA Without Force.Peg extraction task: Contact-Rich Peg-out-Hole
Peg Extraction evaluates contact-rich precision manipulation under severe underwater photometric variation. At the beginning of each rollout, the peg is partially inserted into a mating hole with a radial clearance of 1.5 mm, resulting in tight geometric tolerance and substantial frictional contact along the insertion surface. The robot must establish a stable grasp and extract the peg without losing contact stability; a rollout is considered successful if the peg is completely removed from the hole and securely held by the robot at the end of the episode.
The performance difference between Bi-AQUA and the force-ablated variant is particularly pronounced in this task. Without force input, the policy frequently fails, achieving 0% success in red, purple, and changing illumination and at most 80% even under favorable lighting. In contrast, the full Bi-AQUA model achieves 100% success in all trained lighting modes and maintains high performance under unseen lighting (100% in cyan and changing, 80% in purple). This large margin highlights the importance of force-aware action chunking in scenarios with tight geometric tolerance and sustained frictional contact, especially under photometric shifts that degrade perception quality.
Limitation
Our evaluation is restricted to a single task, robot platform, and tank environment with a finite set of lighting modes, and performance still degrades under extreme combinations of lighting and object appearance. We also do not yet consider variation in water quality, background clutter, or large-scale field deployments. Extending Bi-AQUA to richer skill repertoires, more realistic subsea settings, and integration with other adaptation mechanisms (e.g., domain randomization or online adaptation) are important directions for future work.
Summary & Discussion
Bi-AQUA is the first bilateral control-based imitation learning framework for underwater robot arms that explicitly models lighting at multiple levels. Through a label-free Lighting Encoder implicitly supervised by the imitation objective, FiLM-based conditioning of visual features, and a sequence-level lighting token added to the transformer encoder input, Bi-AQUA adapts its visuomotor behavior to changing lighting while preserving the force-sensitive advantages of bilateral teleoperation. Ablation and generalization experiments show that the lighting-aware components provide complementary gains and that the learned lighting representation transfers to novel objects and visual disturbances. This work bridges terrestrial bilateral control-based imitation learning and underwater manipulation, enabling force-sensitive autonomous operation in challenging marine environments.
6-minute video! Please enjoy!Citation
@misc{tsunoori2025biaquabilateralcontrolbasedimitation,
title={Bi-AQUA: Bilateral Control-Based Imitation Learning for Underwater Robot Arms via Lighting-Aware Action Chunking with Transformers},
author={Takeru Tsunoori and Masato Kobayashi and Yuki Uranishi},
year={2025},
eprint={2511.16050},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2511.16050},
}
Contact
Masato Kobayashi (Assistant Professor, The University of Osaka, Kobe University, Japan)
- X (Twitter)
- English : https://twitter.com/MeRTcookingEN
- Japanese : https://twitter.com/MeRTcooking
- Linkedin https://www.linkedin.com/in/kobayashi-masato-robot/
 * Corresponding author: Masato Kobayashi
* Corresponding author: Masato Kobayashi
Acknowledgments
This work was supported by Research Grant (B) from the Tateisi Science and Technology Foundation, Japan, with M. Kobayashi as the project leader.
We used the underwater robot arm hardware developed in MR-UBi: Mixed Reality-Based Underwater Robot Arm Teleoperation System with Reaction Torque Indicator via Bilateral Control. We thank Kohei Nishi for his contributions to the hardware development.