Bi-HIL: Bilateral Control-Based Multimodal Hierarchical Imitation Learning via Subtask-Level Progress Rate and Keyframe Memory for Long-Horizon Contact-Rich Robotic Manipulation
The University of Osaka / Kobe University
Thanpimon Buamanee (Master’s student, 2nd year) is primarily responsible for unimanual robot learning model construction and video.
Masato Kobayashi (Assistant Professor, project tech lead) is primarily responsible for bimanual robot learning model construction, robot control software, website and video.



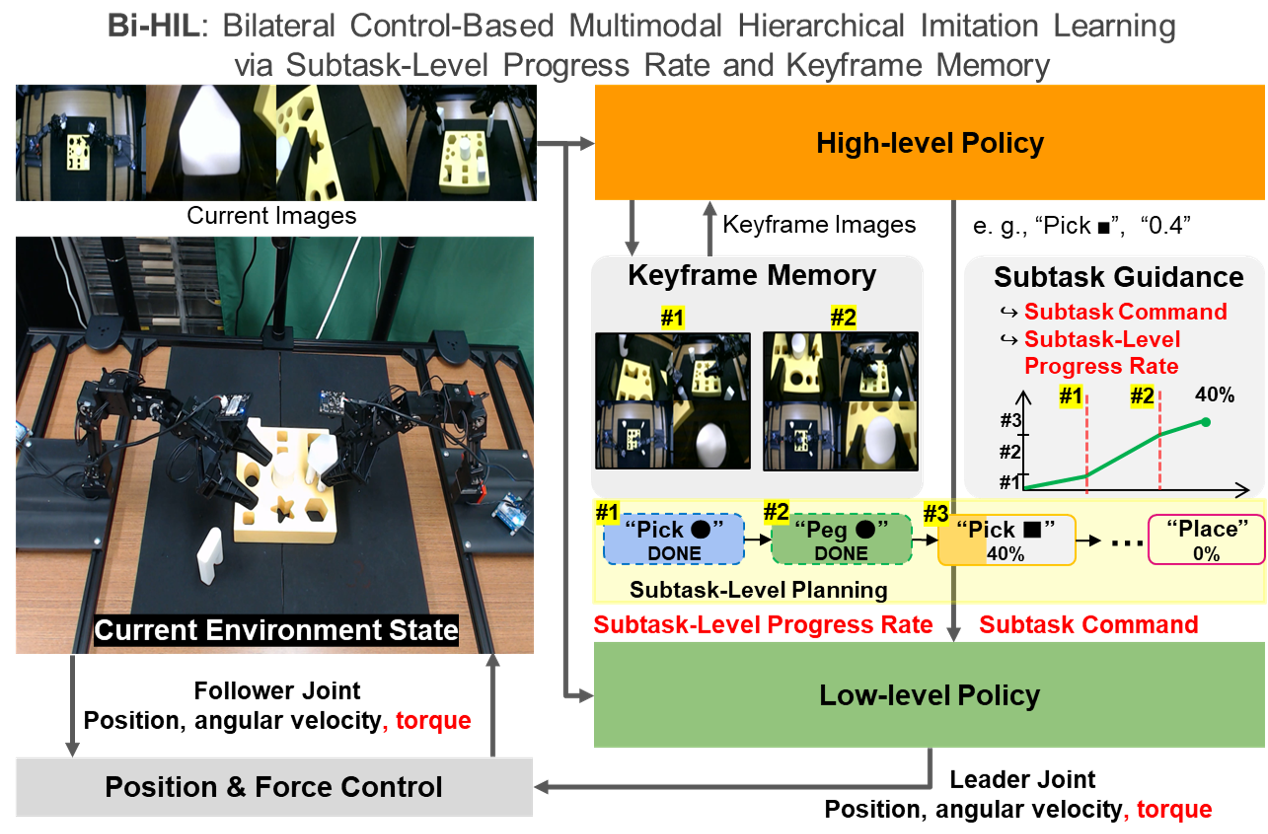
Concept of Bi-HIL
Bi-HIL Model
Overview of Bi-HIL
Bi-HIL adopts a hierarchical framework consisting of a high-level policy and a low-level policy. High-level policy performs subtask-level reasoning by predicting subtask commands and subtask-level progress rate, while maintaining task memory using representative keyframes. Low-level policy predicts motor actions conditioned on visual observations, robot joint states, and high-level guidance.
During inference, the high-level policy provides temporally grounded task context, and the low-level policy executes continuous control actions based on this structured information. This hierarchical design enables robust execution of long-horizon manipulation tasks.
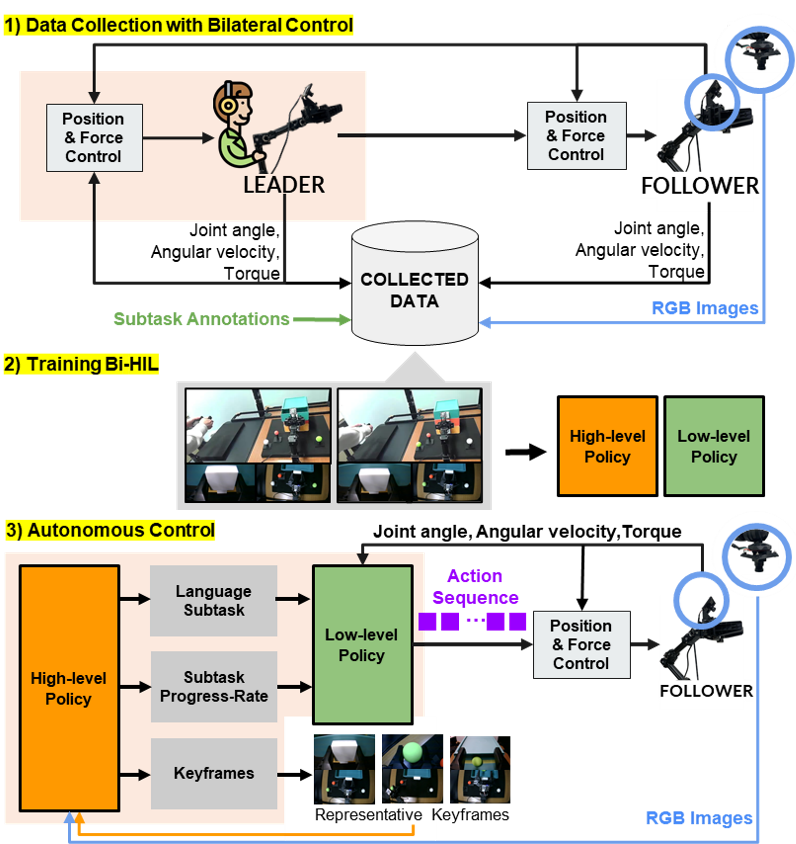
Data Collection: Four-Channel Bilateral Control
Bi-HIL employs a four-channel bilateral control method for data collection, in which the leader robot is controlled by the operator and the follower robot interacts with the environment and provides force feedback to the leader. The control objective enforces synchronized motion between the leader and follower, and ensures force consistency via an action–reaction relationship. Joint angles, angular velocities, and torques are recorded. After data collection, subtask boundaries are manually annotated based on visual observations using natural language instructions. These annotations supervise high-level policy training.
High-Level Policy
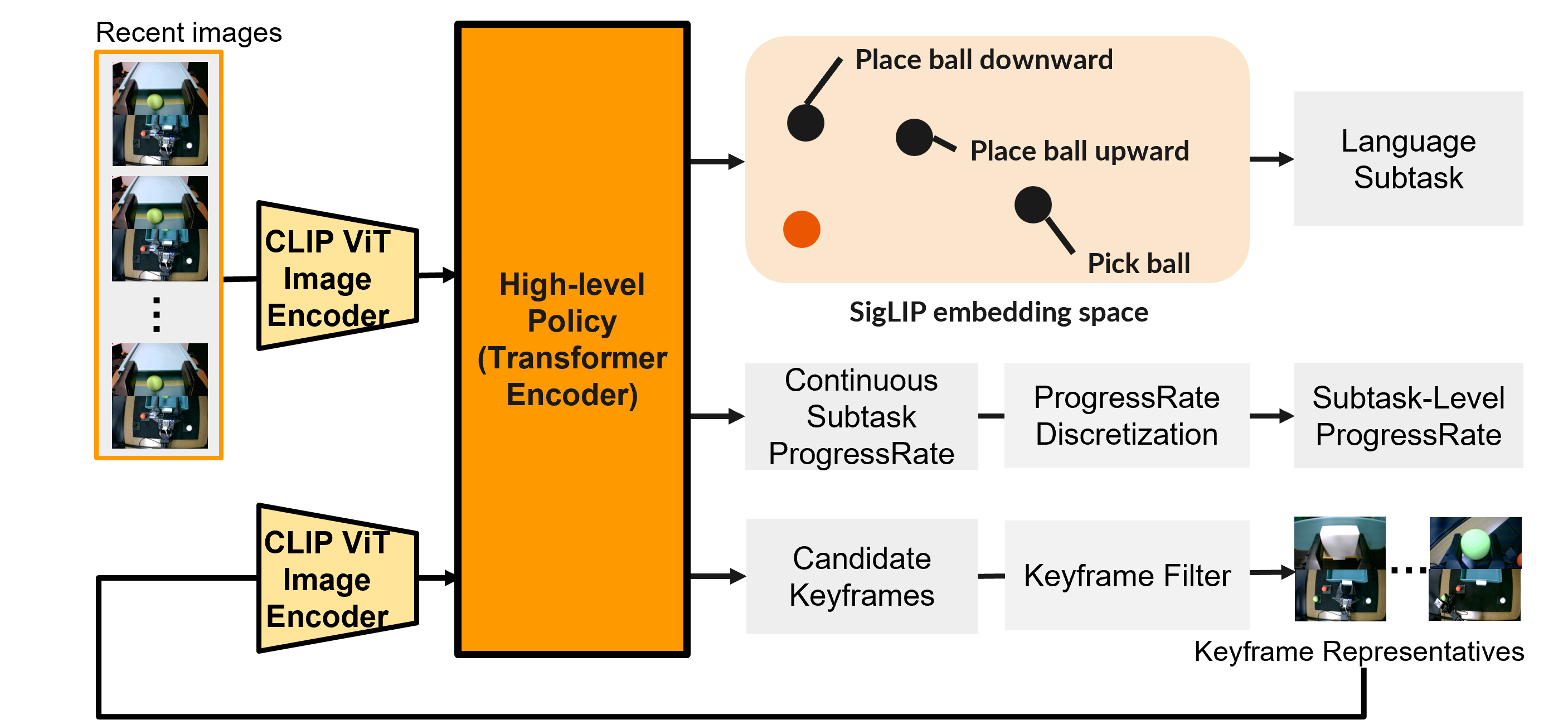
High-Level Policy Architecture
The high-level policy is a transformer encoder that performs subtask-level reasoning. Architecture is (i) keyframe-based memory inspired by MemER and (ii) subtask-level progress prediction. These components enable temporally consistent decision-making under partial observability.
At each high-level timestep, the policy receives a window of the most recent observations from each camera and a set of previously selected keyframes. The policy predicts: (i) a subtask command, (ii) a subtask-level progress rate ( p_t \in [0,1] ), and (iii) keyframe scores for each frame in the current window.
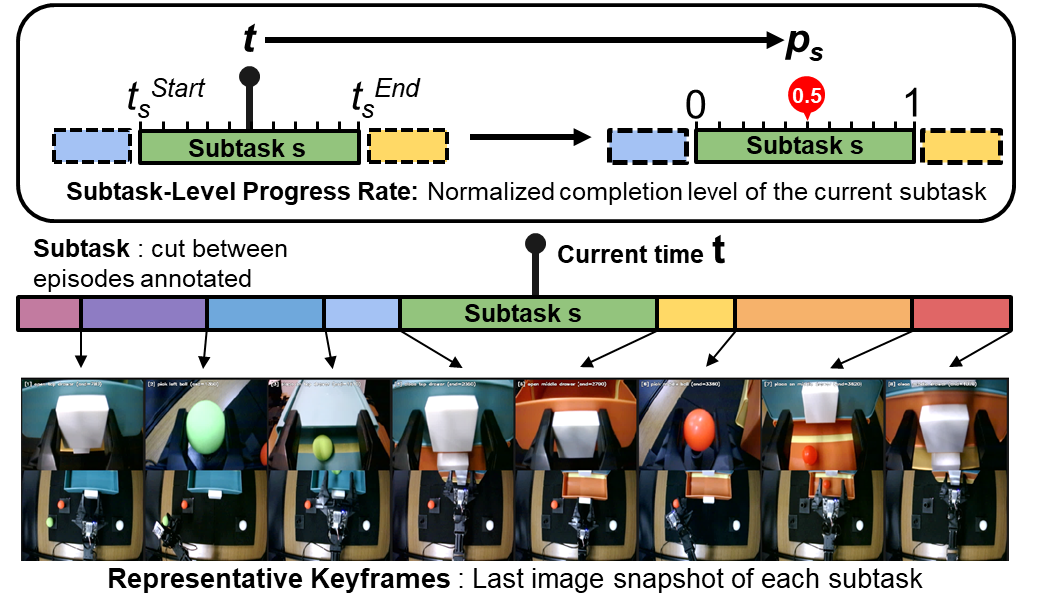
Definition of Representative Keyframes and Subtask-Level Progress Rate
The subtask-level progress rate represents the normalized completion ratio of the active subtask and is reset to zero when a new subtask begins. Keyframes serve as visual anchors of completed subtasks.
Low-Level Policy
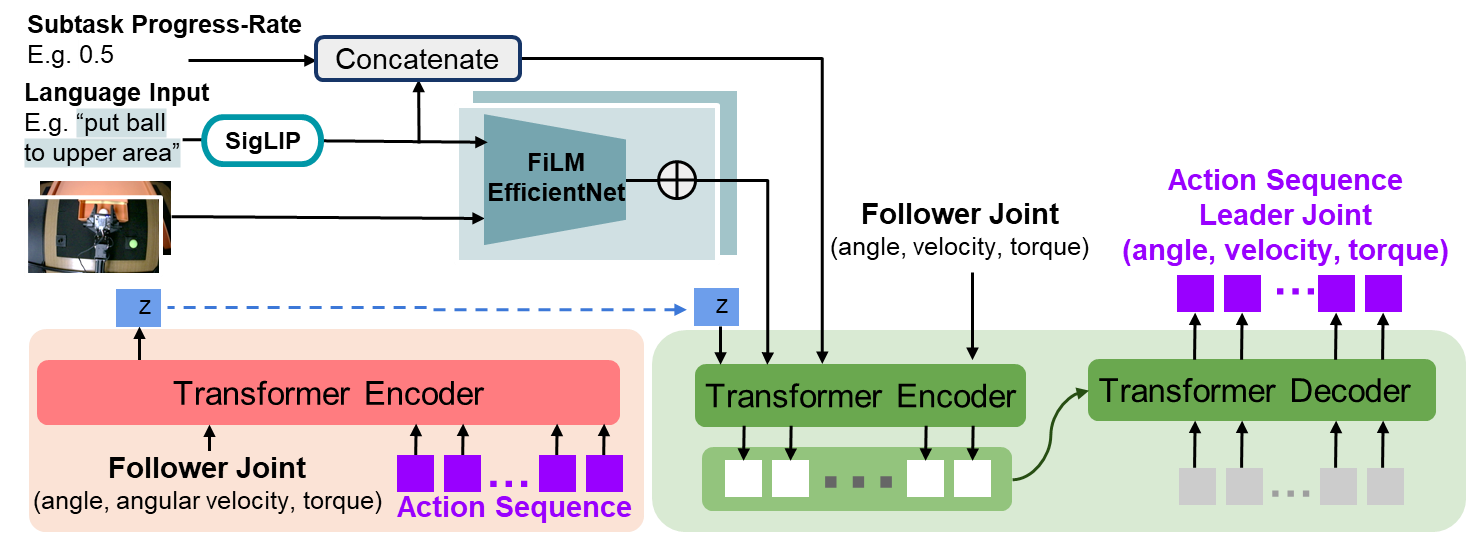
Low-Level Policy Architecture
The low-level policy is implemented as a transformer-based conditional variational autoencoder (CVAE). The model receives the subtask-level progress rate and the SigLIP-embedded subtask instruction predicted by the high-level policy, along with the current RGB images and the follower robot’s joint states (angle, angular velocity, and torque). Based on these inputs, the low-level policy predicts the next joint states of the leader robot (angle, angular velocity, and torque). The SigLIP-encoded subtask instruction and RGB images are processed by a FiLM-conditioned EfficientNet, where the language embedding modulates the visual features via FiLM. Subtask-level progress rate is discretized into ten uniform levels to improve robustness.
Execution
Unimanual Experiments
Hardware

Data Collection of Put-Three-Balls-in-Drawer Task
Unimanual experiments were conducted using OpenMANIPULATOR-X robotic arms developed by ROBOTIS. The setup consists of two robots: a leader robot operated by a human demonstrator and a follower robot interacting with the environment. Each robot is equipped with 4 DOF for arm motion and an additional DOF for the gripper, resulting in a total of 5 actuated joints. The control cycle was set to 1000 Hz. Two RGB cameras were positioned on top and in the gripper area of the follower robot to record observations at 100 Hz.
Task Setting
LeftRightWe evaluate the proposed method on the long-horizon manipulation task Put-Three-Balls-in-Drawer, in which the robot sequentially places green, red, and white balls into their corresponding drawers from top to bottom. The positions of the green and white balls are interchangeable, requiring the robot to rely on visual observations to determine the correct execution order.
This task presents three challenges: long temporal duration (59.2 s on average), visually similar subtasks, and ambiguous initial configurations. The task consists of 12 subtasks, and the execution order depends on the initial ball placement (Left configuration vs. Right configuration).
Training Setting
Six demonstration episodes were collected using bilateral control (three Left, three Right). Each episode was 57.3–61.2 seconds. Demonstrations were manually annotated with subtask boundaries and augmented using DABI, increasing the dataset to 60 demonstrations. These augmented data were used to train Bi-ACT, Bi-HIL, and ablation variants of Bi-HIL.
Experimental Results
Unimanual Keyframe and Subtask-level Progress RateLeft (Realtime)Right (Realtime)| Model Name | Success (Left) | Success (Right) |
|---|---|---|
| Bi-ACT (Baseline) | 60% | 100% |
| Bi-HIL (w/o KF&SPR) | 30% | 30% |
| Bi-HIL (w/o SPR) | 50% | 50% |
| Bi-HIL (w/o KF) | 70% | 70% |
| Bi-HIL (Proposed) | 100% | 100% |
KF: Keyframe, SPR: Subtask-Level Progress Rate
The proposed Bi-HIL model is the only method to achieve a 100% success rate on both configurations (5/5 for Left, 5/5 for Right), demonstrating superior performance on this task.
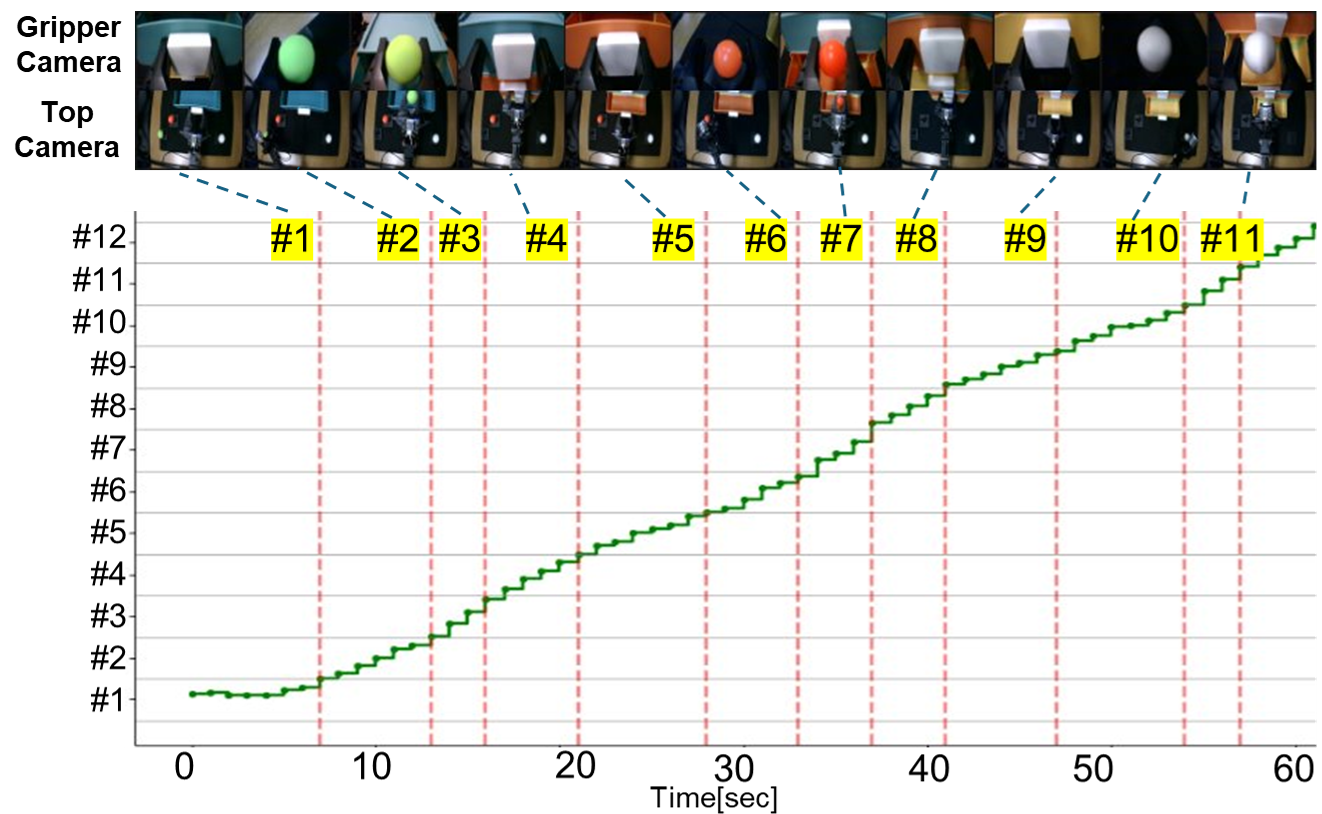
Put-Three-Balls-in-Drawer: Subtask-Level Progress Rate and Keyframe Memory
The visualization shows a clear progression of predicted subtasks and subtask-level progress rate over time. Keyframes (red) are predicted near subtask boundaries, demonstrating effective memory selection. Ablation results demonstrate that both keyframe memory and subtask-level progress rate are essential for stable reasoning and reliable execution.
Bimanual Experiments
Hardware

Experimental Setup (Bimanual)

Data Collection of 6-Cup Downstack and 4-Peg-in-Hole
ALPHA-α were used for experiments of bimanual robotic manipulation. A total of four robots were utilized: two leader robots operated by the human operator and two follower robots. Each robot has six DOF for arm movement and an additional DOF for the gripper, utilizing a total of seven motors. The bilateral control cycle was set to 1000 Hz. Four RGB cameras were placed on top, on the sides, and at both the right and left gripper areas of the follower robots to record observations.
Task Setting
6-Cup Downstack: The task is performed through a sequence of structured pick-and-insert actions, progressively nesting the upper tiers into the base layer and consolidating the cups into a single centralized stack.
4-Peg-in-Hole: The task consists of a sequence of precise pick-and-insert actions, where the robot grasps geometric pegs and inserts them into their corresponding holes. The task emphasizes accurate alignment and force-sensitive insertion under contact-rich conditions.
Experimental Results
6-Cup Downstack
Bimanual Keyframe and Subtask-level Progress RateRealtime| Model Name | Success |
|---|---|
| Bi-ACT (w/o Force) | 20% |
| Bi-ACT | 60% |
| Bi-HIL | 80% |
The proposed Bi-HIL achieves the highest performance with an 80% success rate (4/5). Compared to Bi-ACT, Bi-HIL shows improved stability in the later merging stages.
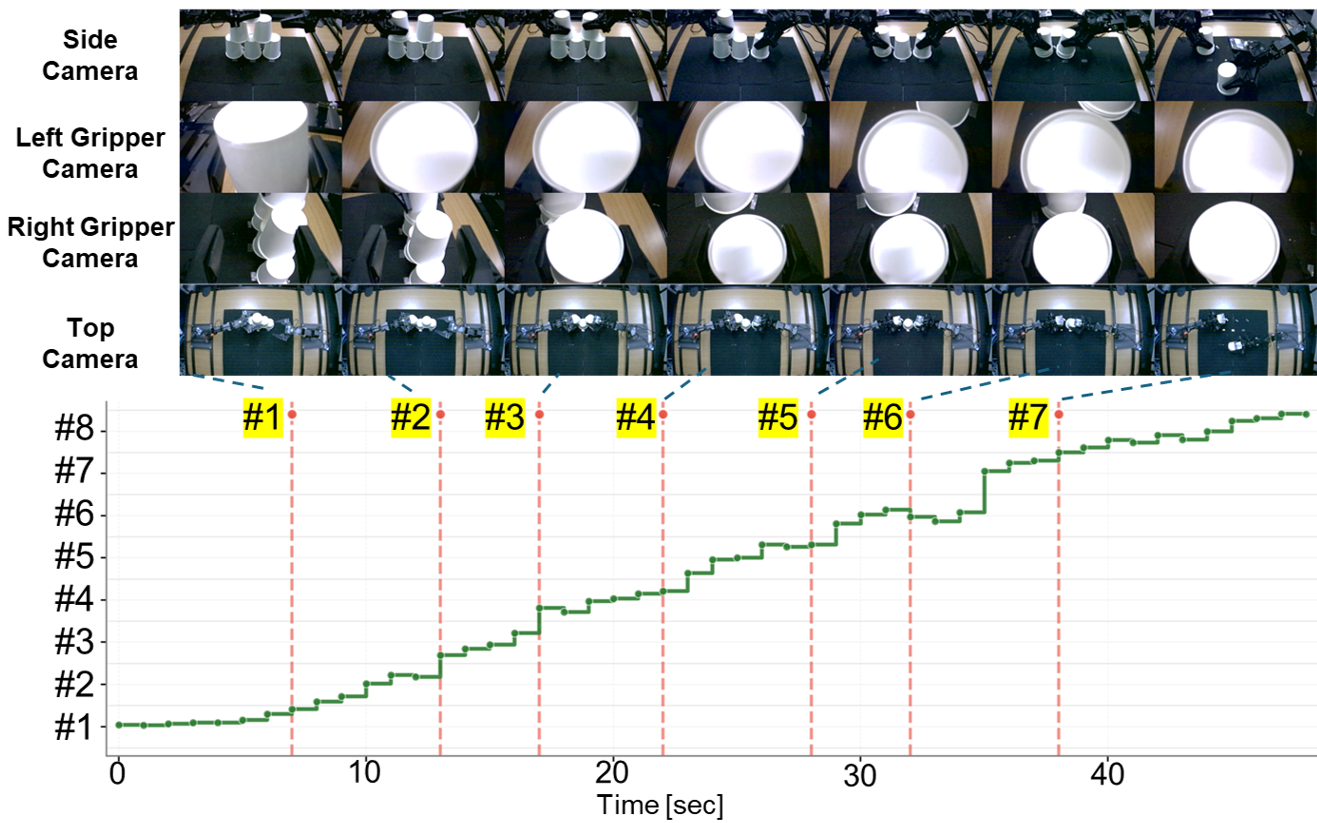
6-Cup Downstack: Subtask-Level Progress Rate and Keyframe
4-Peg-in-Hole
Bimanual Keyframe and Subtask-level Progress RateRealtime| Model Name | Success |
|---|---|
| Bi-ACT (w/o Force) | 0% |
| Bi-ACT | 20% |
| Bi-HIL | 80% |
Bi-HIL achieves 80% success rate (4/5). All trials successfully complete subtasks #1–#4, and the majority progress reliably through the remaining insertion phases. Hierarchical task decomposition combined with force-aware low-level control substantially improves reliability in contact-rich assembly tasks.
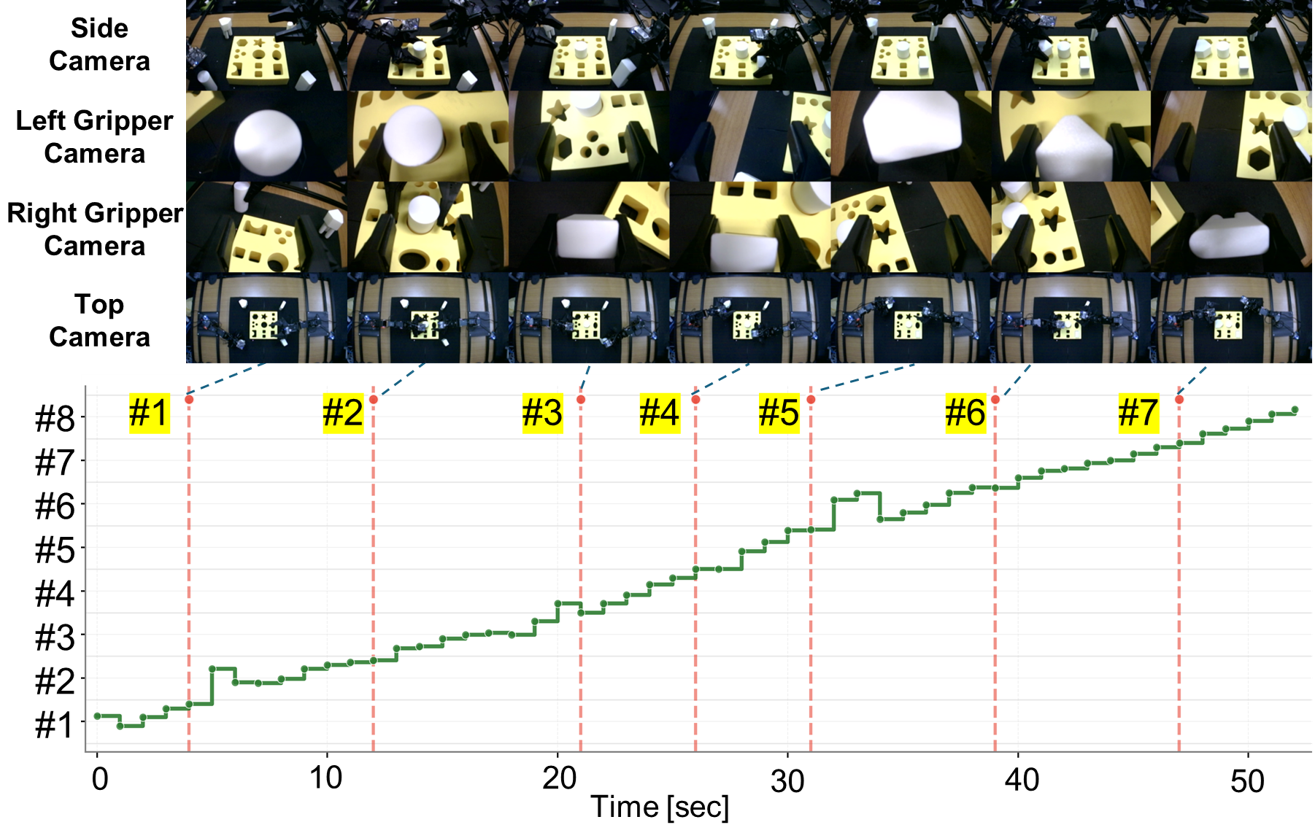
4-Peg-in-Hole: Subtask-Level Progress Rate and Keyframe
Conclusion
We presented Bi-HIL, a bilateral control-based multimodal hierarchical imitation learning framework for long-horizon contact-rich manipulation. Bi-HIL couples a high-level policy that predicts subtask commands and a resettable subtask-level progress rate with a force-aware low-level policy learned from bilateral demonstrations.
Experiments on real robots show that Bi-HIL improves robustness over baselines and ablated variants on both unimanual and bimanual settings. On the unimanual task, Bi-HIL achieves reliable long-horizon execution with stable subtask transitions. On bimanual contact-rich tasks, Bi-HIL consistently outperforms force-aware baseline policies, particularly in later subtasks. These results indicate that explicit subtask-level phase modeling, together with keyframe memory and force-aware control, is critical for robust long-horizon manipulation.
Citation
@misc{buamanee2026bihilbilateralcontrolbasedmultimodal,
title={Bi-HIL: Bilateral Control-Based Multimodal Hierarchical Imitation Learning via Subtask-Level Progress Rate and Keyframe Memory for Long-Horizon Contact-Rich Robotic Manipulation},
author={Thanpimon Buamanee and Masato Kobayashi and Yuki Uranishi},
year={2026},
eprint={2603.13315},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2603.13315},
}
Contact
Masato Kobayashi (Assistant Professor, The University of Osaka, Japan)
- X (Twitter)
- English : https://twitter.com/MeRTcookingEN
- Japanese : https://twitter.com/MeRTcooking
- LinkedIn https://www.linkedin.com/in/kobayashi-masato-robot/