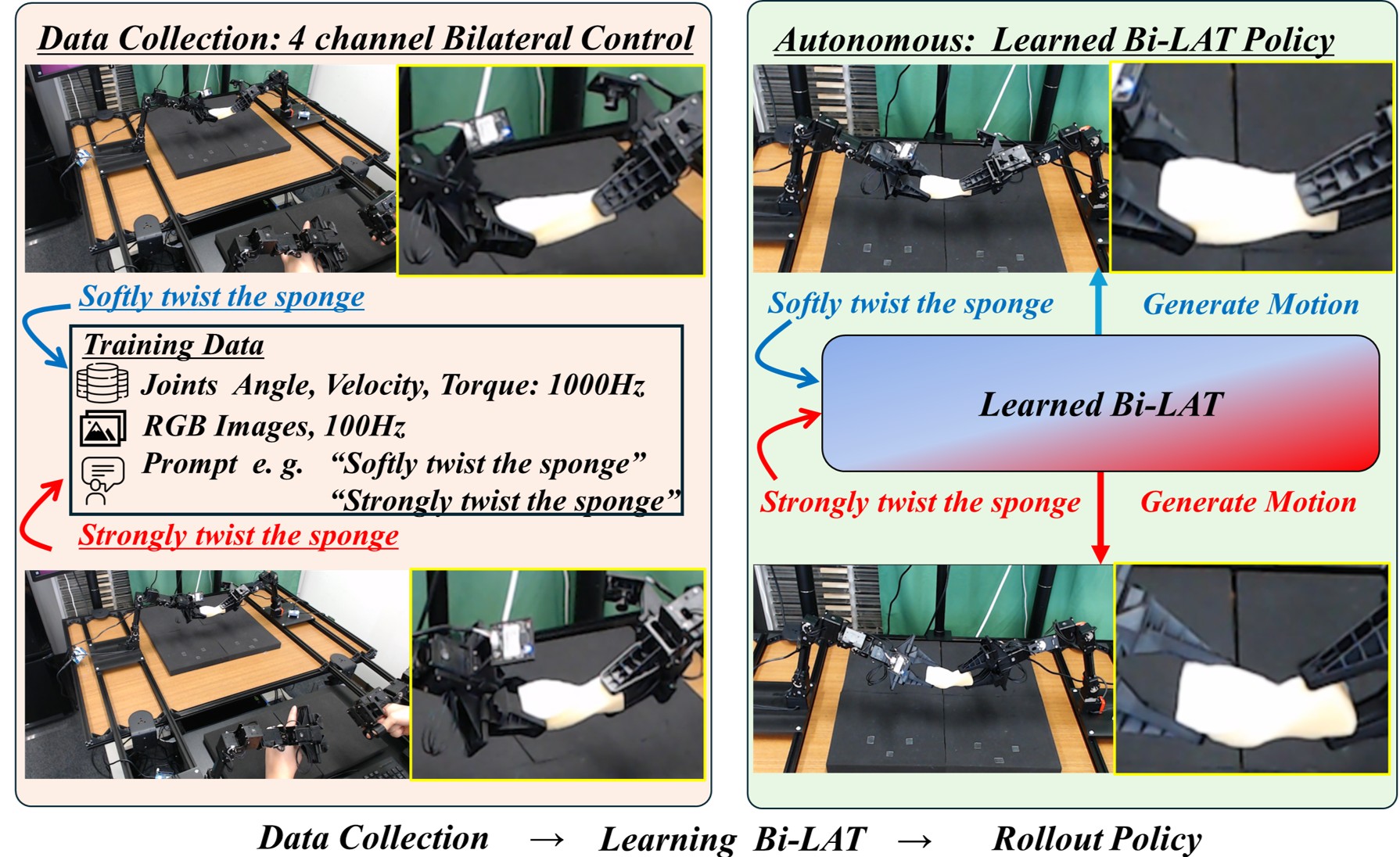
Bi-LAT: Bilateral Control-Based Imitation Learning via Natural Language and Action Chunking with Transformers
The University of Osaka / Kobe University



Bi-LAT Model
Bi-LAT Model
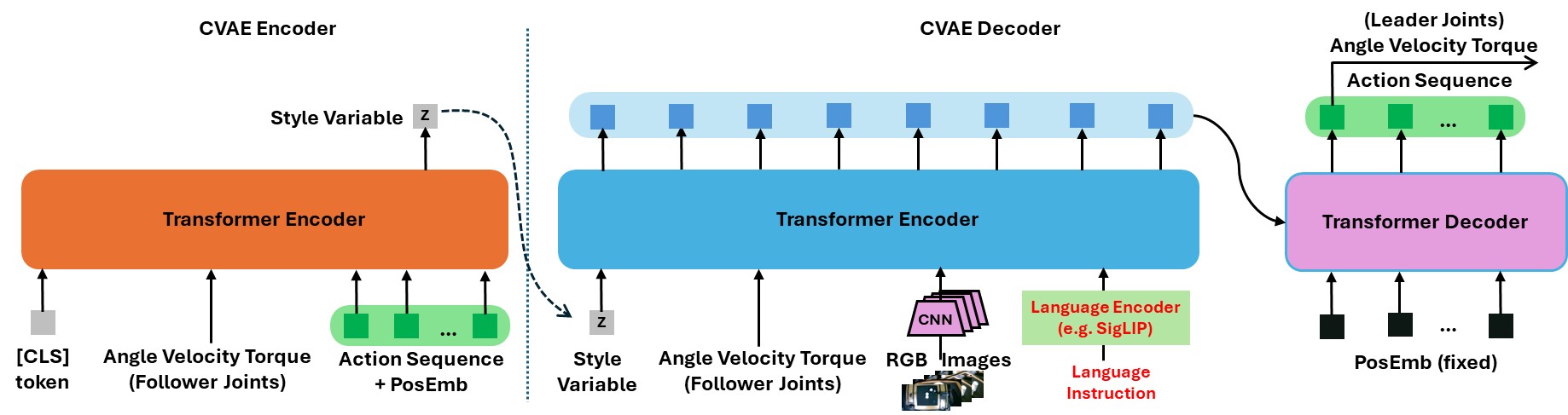
The Bi-LAT learning model is built upon a Transformer-driven Conditional Variational Autoencoder (CVAE) architecture. In this framework, the model receives the follower robot joints’ angle, velocity, and torque data along with corresponding visual inputs and natural language instructions. Based on this multimodal input, the model outputs sequences of action chunks that specify the predicted joint angles, velocities, and torques of leader robots. Natural language instructions are processed by a dedicated language encoder (LE), which converts the textual commands into fixed-length vector representations.
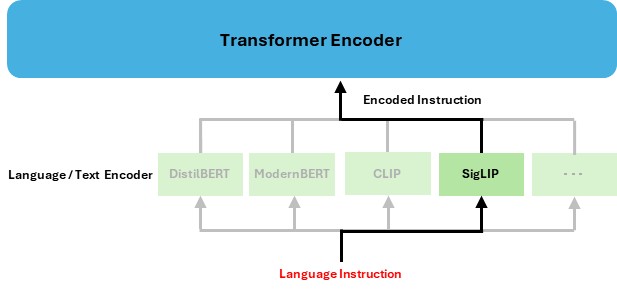
Language/ Text Encoder
In this paper, we select four language encoders among many available options, namely DistilBERT, ModernBERT, CLIP, and SigLIP. These linguistic features are integrated with visual features extracted from ResNet-18 and the follower robot’s joint angles, velocities, and torques to form a comprehensive latent representation. This representation is then passed through the CVAE-based Transformer decoder, which predicts the future leader robot’s actions as a series of action chunks. The learning process is driven by minimizing the error between the predicted leader joint data and the corresponding ground-truth data collected during bilateral control teleoperation.
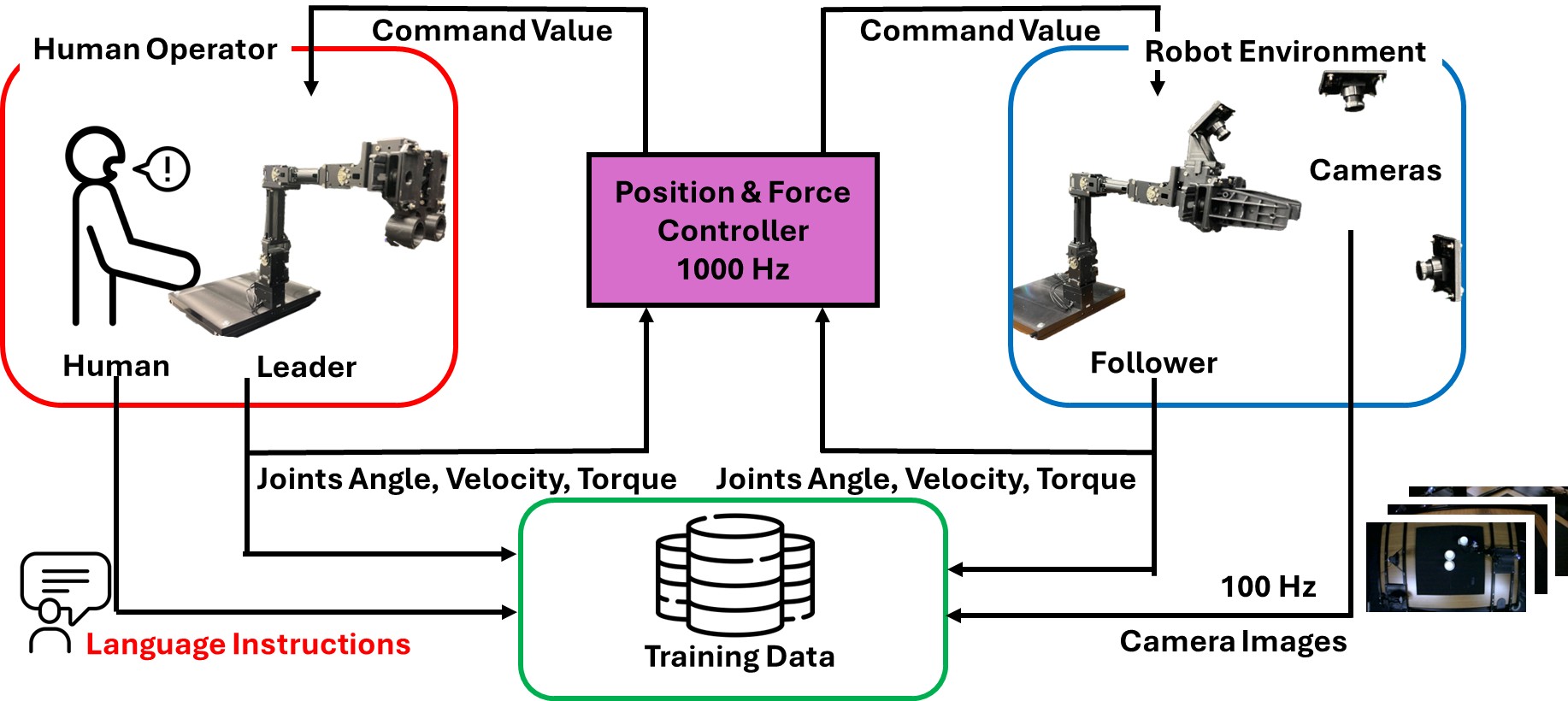
Data Collection:four-channel bilateral control
Bi-LAT Data Collection
Inference
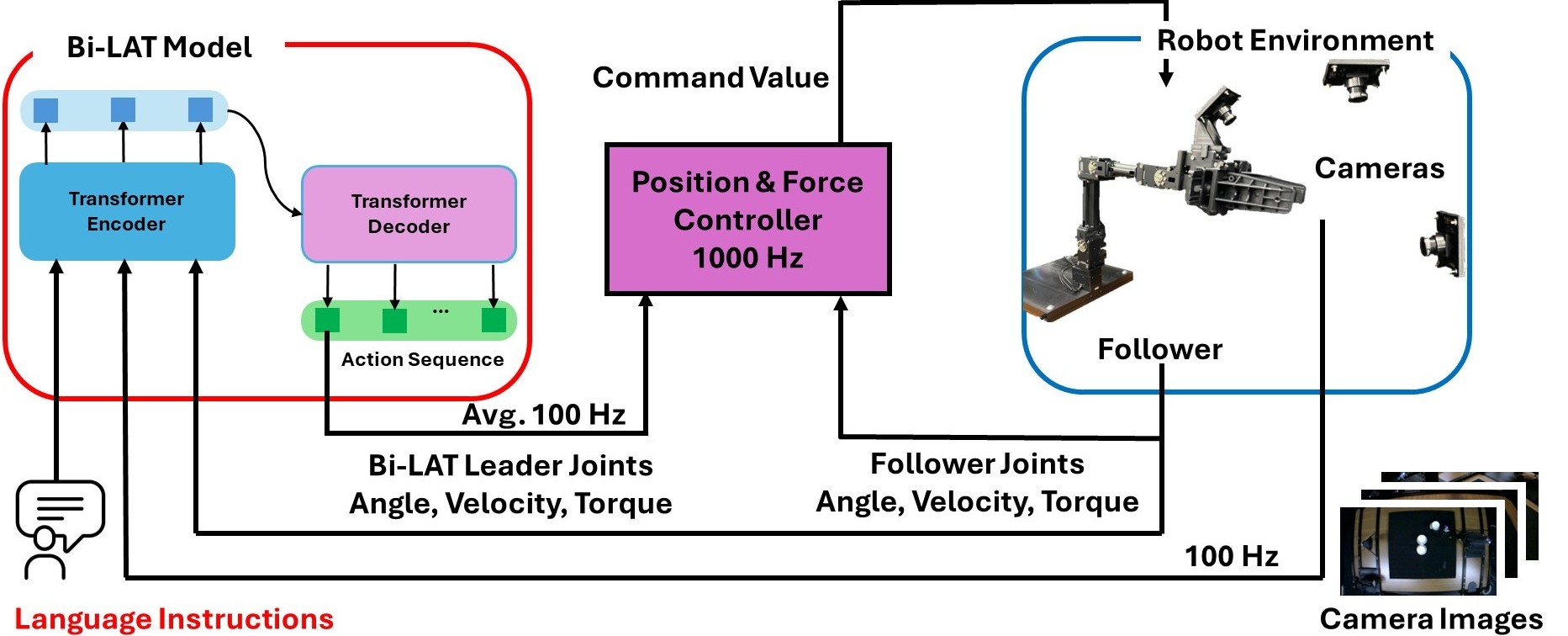
Bi-LAT Inference
Unimanual Experiments
Data Collection
Setup:
- Hardware: OpenManipulator-X with five joints (including a gripper) and three RGB cameras.
- Task: The robot stacks paper cups under two conditions:
- “Softly grasp the cup” – lighter grip force
- “Strongly grasp the cup” – firmer grip force
softly grasp the cup (Real-Time, 1X)
strongly grasp the cup (Real-Time, 1X)
Joint angles, angular velocities, and torques were recorded from the leader and follower robots using the four-channel bilateral control system, operating at a control frequency of 1000 Hz. This resulted in 15-dimensional joint data (3 values × 5 joints) per robot, and 30-dimensional joint data in total across both robots, capturing detailed motor-level dynamics essential for imitation learning. Simultaneously, RGB images were captured from three cameras at a frequency of 100 Hz.
Eeach demonstration was paired with a natural language instruction. Among the six demonstrations, three involved “softly grasp the cup”, while the other three involved “strongly grasp the cup.” Histograms for Joint5 (Gripper) angle and torque during the grasping phase support these findings.
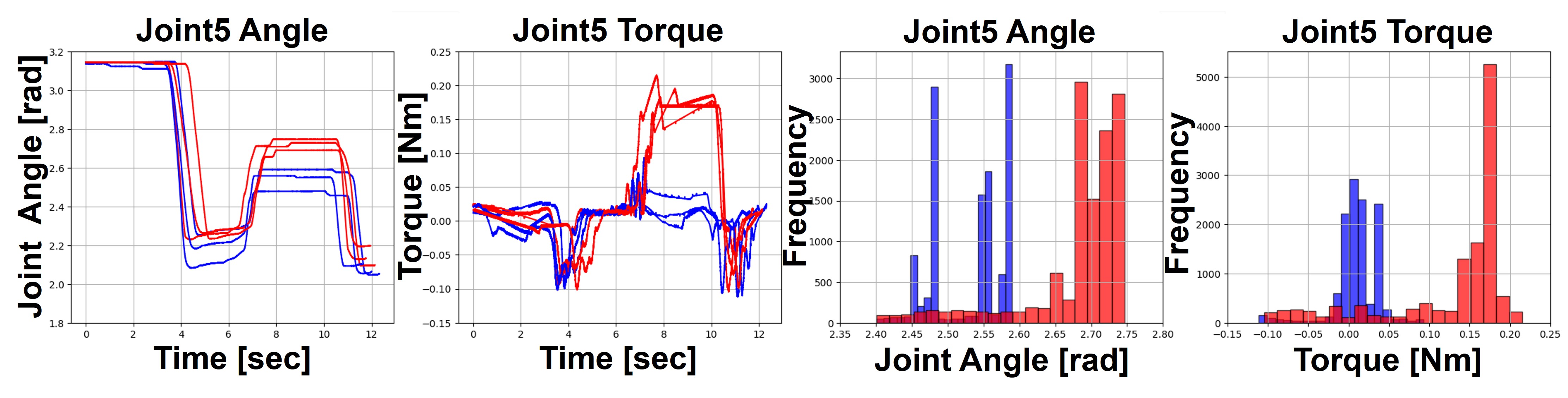
Training Data of Follower Robots
Moreover, to augment the training data, we employed the DABI. Based on this dataset, we trained Bi-ACT, and Bi-LAT using DistilBERT, ModernBERT, CLIP text encoder, and SigLIP text encoder. We configured Bi-LAT models with 4 encoder layers and 7 decoder layers.
Autonomous:
Results:
- 100% success rate in all trials.
- Force Modulation:
- Without language cues (conventional Bi-ACT), the model produced a uniform, strong grasp.
- Bi-LAT with different language encoders showed varying differentiation in force.
- SigLIP-based Bi-LAT most accurately reproduced the training distributions, clearly distinguishing between soft and strong grasps.
Bi-LAT&SigLIP Text Encoder
softly grasp the cup (Real-Time, 1X)
strongly grasp the cup (Real-Time, 1X)
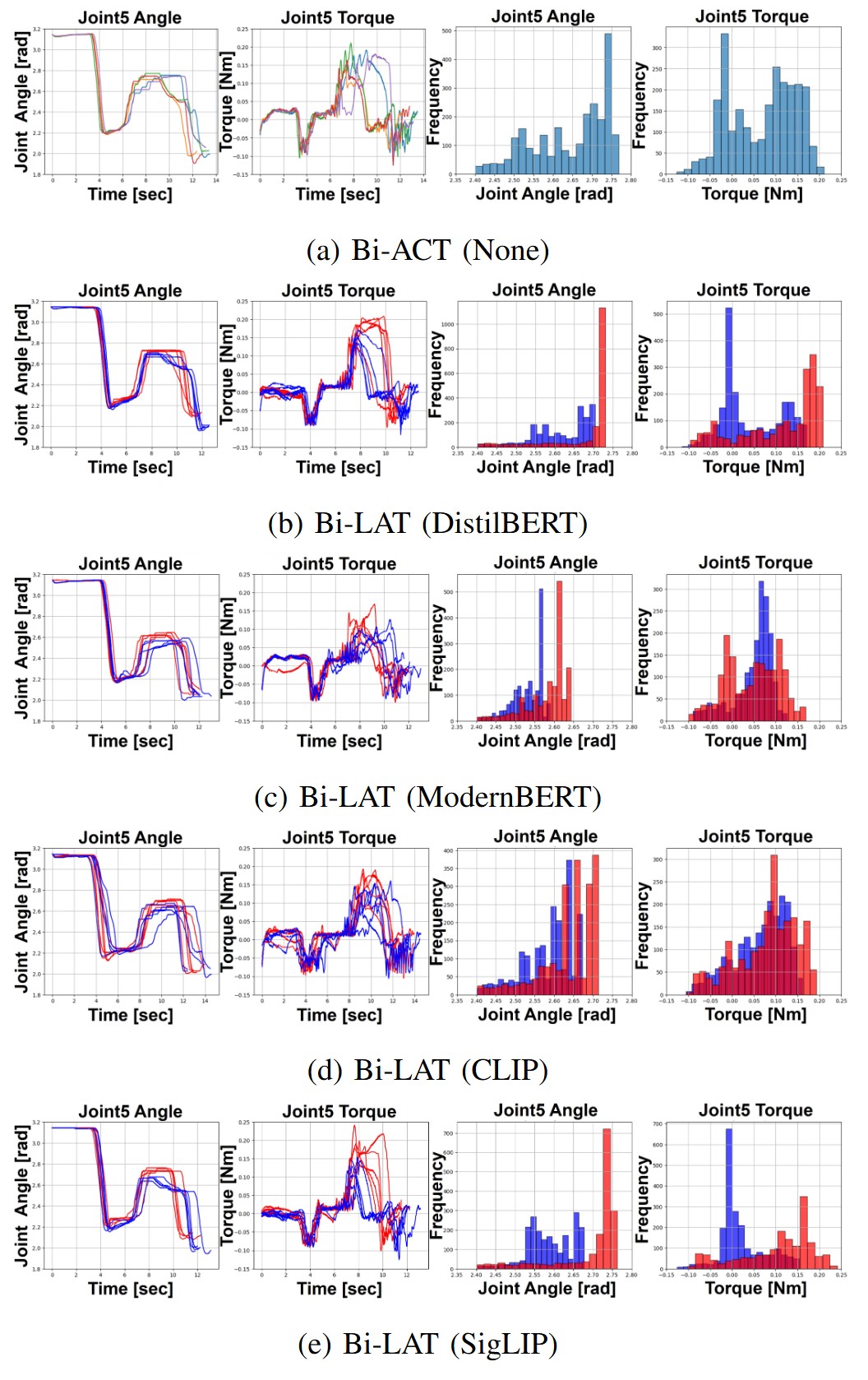
Results of Gripper Joint5 Angle and Torque
In the conventional Bi-ACT model, which was trained without language inputs, data from both “softly” and “strongly” demonstrations were merged into a single training set. As a result, the model treated both force modalities as equivalent aspects of the same task. When no language instruction was provided, the inferred joint angle and torque profiles were biased toward strong force characteristics, with joint angles distributed around 2.75 rad and torques between 0.10 and 0.20 Nm. This result indicates that the Bi-ACT model is unable to differentiate between the “softly” and “strongly” actions, thereby failing to encode the nuanced force requirements for varying task conditions. These findings underscore the necessity of incorporating natural language cues to guide force modulation, ultimately enabling a more precise and context-aware imitation learning process.
We tested action-oriented prompts, “softly grasp the cup” and “strongly grasp the cup’’, to determine whether Bi-LAT could replicate the training distributions. While the overall task was executed successfully, time series graph and histogram analyses revealed varying levels of differentiation among the language models. For example, DistilBERT produced a joint angle distribution for “softly grasp the cup” between 2.65 and 2.7 rad, while for “strongly grasp the cup” the joint angles exceeded 2.7 rad, and corresponding torques were near 0 Nm and around 0.20 Nm, respectively. However, compared to the training data, the motions generated for “softly grasp the cup” exhibited higher than expected angles and torques. In contrast, the results for ModernBERT and CLIP demonstrated some differentiation in the maximum values, but the overall distributions did not clearly distinguish between the two conditions. Most notably, SigLIP provided the clearest separation, with the inference data for each instruction closely matching the training distributions.
These findings confirm that incorporating natural language cues into a bilateral control-based imitation learning framework is essential for precise force modulation. By aligning with the distributions in the training data, SigLIP-based Bi-LAT can effectively map language instructions to the appropriate joint angle and torque profiles.
Bimanual Experiments
Data Collection
Setup:
- Hardware: ALPHA‑α bimanual robots with 7 degrees of freedom (including grippers) and four RGB cameras.
- Task: The robot performs a sponge-twisting task with two instructions:
- “Softly twist the sponge”
- “Strongly twist the sponge”
softly twist the sponge (Real-Time, 1X)
strongly twist the sponge (Real-Time, 1X)
Joint angles, angular velocities, and torques were recorded from both the leader and follower robots using the 4-channel bilateral control system, operating at the control frequency of 1000 Hz. This resulted in 21-dimensional joint data (3 values × 7 joints) per robot, and 84-dimensional data in total across both robots, capturing detailed motor-level dynamics essential for imitation learning. Simultaneously, RGB images were captured from four cameras at a frequency of 100 Hz.
Each demonstration was paired with a natural language instruction; among the six demonstrations, three involved “strongly twist the sponge”, while the other three involved “softly twist the sponge.” The histograms were generated from data captured after six seconds, corresponding to the interval in which the sponge was actively grasped.

Training Data of Follower Robots
By applying DABI, we expanded the original six demonstrations into 60 by downsampling the 1000 Hz control data to 100 Hz, thereby increasing the dataset size by a factor of ten. Based on this dataset, we trained Bi-LAT using the SigLIP text encoder and configured the model with 4 encoder layers and 7 decoder layers.
Autonomous:
Results:
- Soft Twist: 100% success across all stages (Pick, Lift, Twist).
- Strong Twist: Overall 80% success (one trial failed during the twisting stage due to grip loss).
- Analysis:
- Despite similar spatial trajectories, torque profiles varied significantly between instructions, confirming that Bi-LAT with SigLIP can modulate force as specified by natural language.
Bi-LAT&SigLIP Text Encoder
softly twist the sponge (Real-Time, 1X)
strongly twist the sponge (Real-Time, 1X)
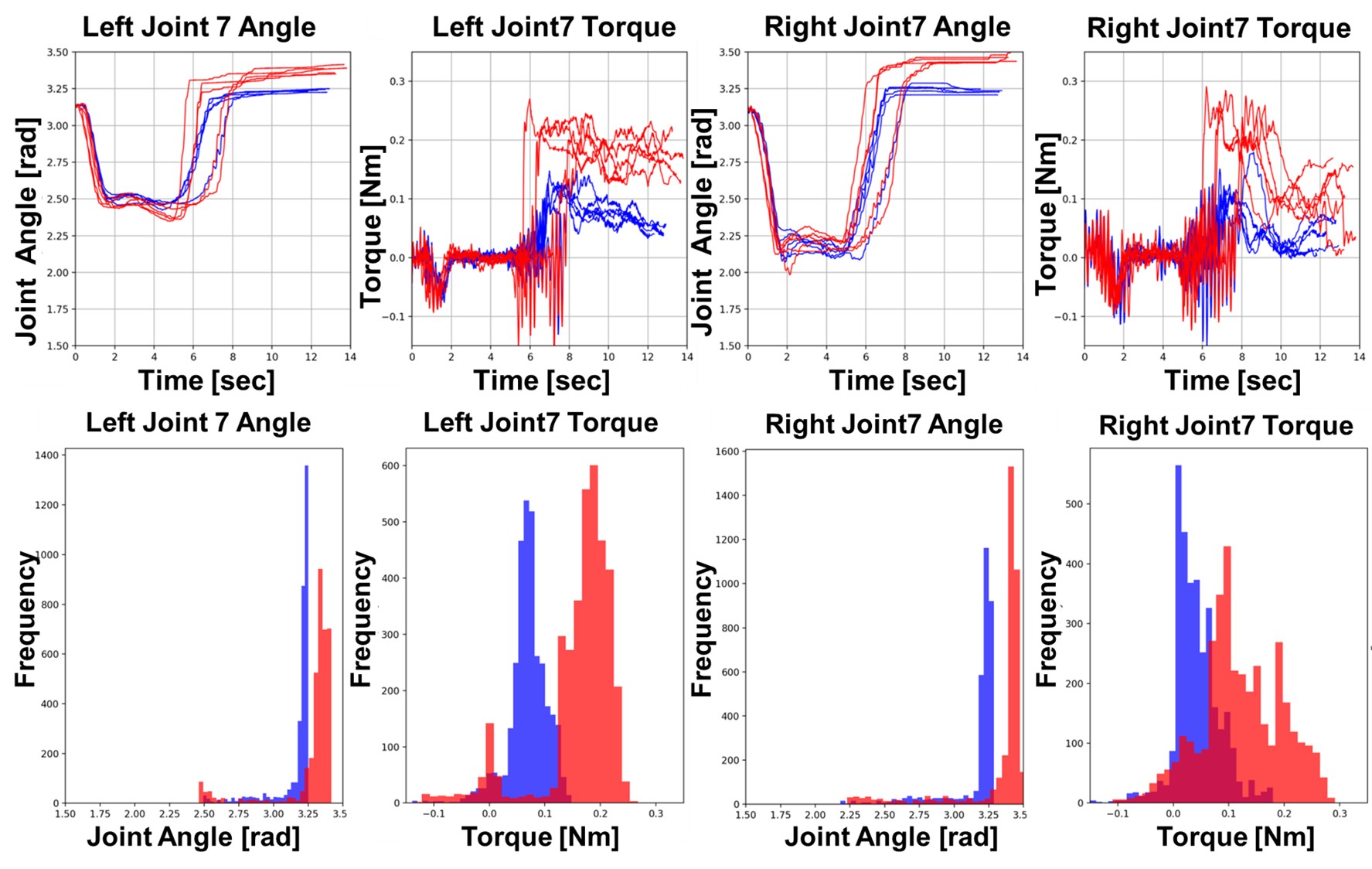
Results of Follower Robots via Bi-LAT
Failed Case
Failed: strongly twist the sponge (Real-Time, 1X)
Citation
@misc{kobayashi2025bilat,
title={Bi-LAT: Bilateral Control-Based Imitation Learning via Natural Language and Action Chunking with Transformers},
author={Takumi Kobayashi and Masato Kobayashi and Thanpimon Buamanee and Yuki Uranishi},
year={2025},
eprint={2504.01301},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2504.01301},
}
Reference
- ALPHA-α and Bi-ACT Are All You Need: Importance of Position and Force Control and Information in Imitation Learning for Unimanual and Bimanual Robotic Manipulation https://mertcookimg.github.io/alpha-biact/
Contact
Masato Kobayashi (Assistant Professor, The University of Osaka , Japan)
- X (Twitter)
- English : https://twitter.com/MeRTcookingEN
- Japanese : https://twitter.com/MeRTcooking
- Linkedin https://www.linkedin.com/in/kobayashi-masato-robot/
 * Corresponding author: Masato Kobayashi
* Corresponding author: Masato Kobayashi