Bi-VLA: Bilateral Control-Based Imitation Learning via Vision-Language Fusion for Action Generation
The University of Osaka / Kobe University



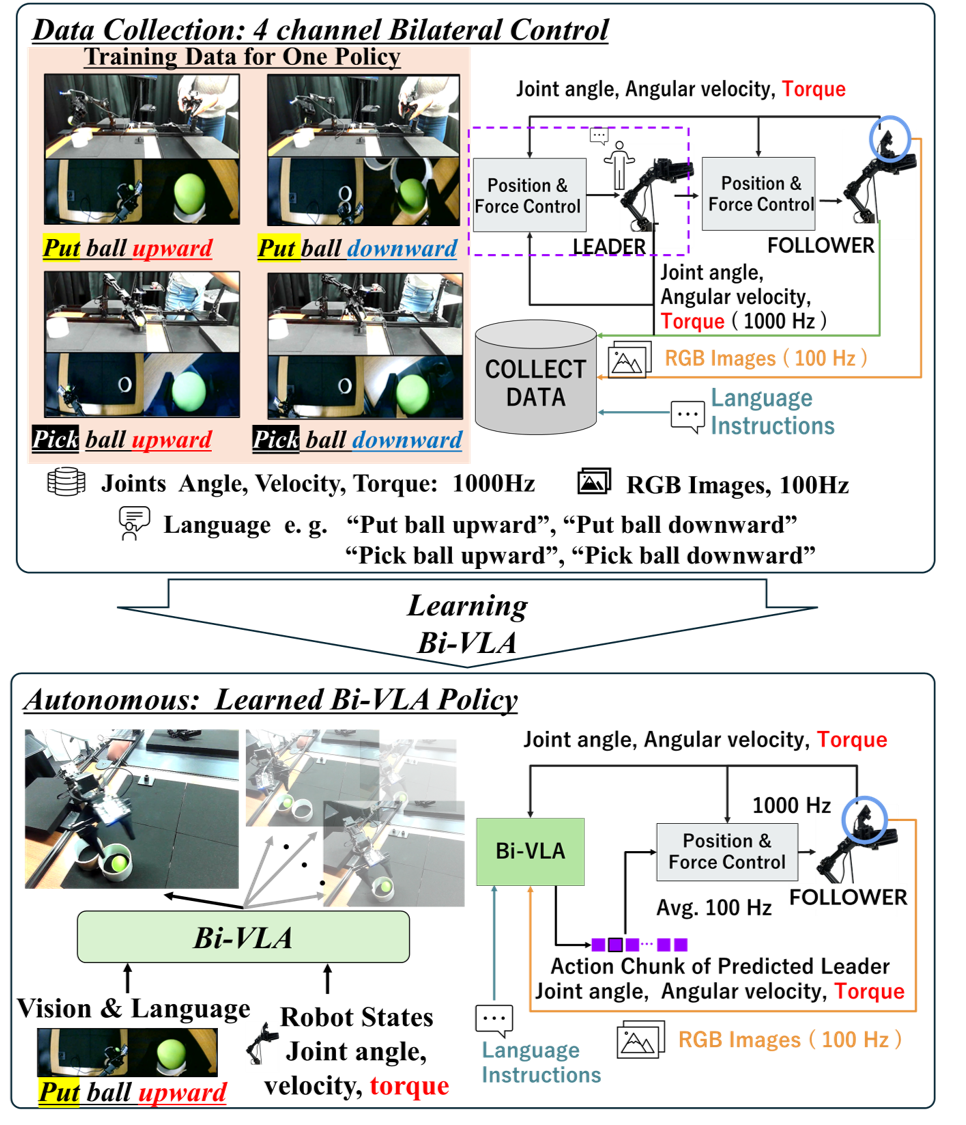
Bi-VLA Model
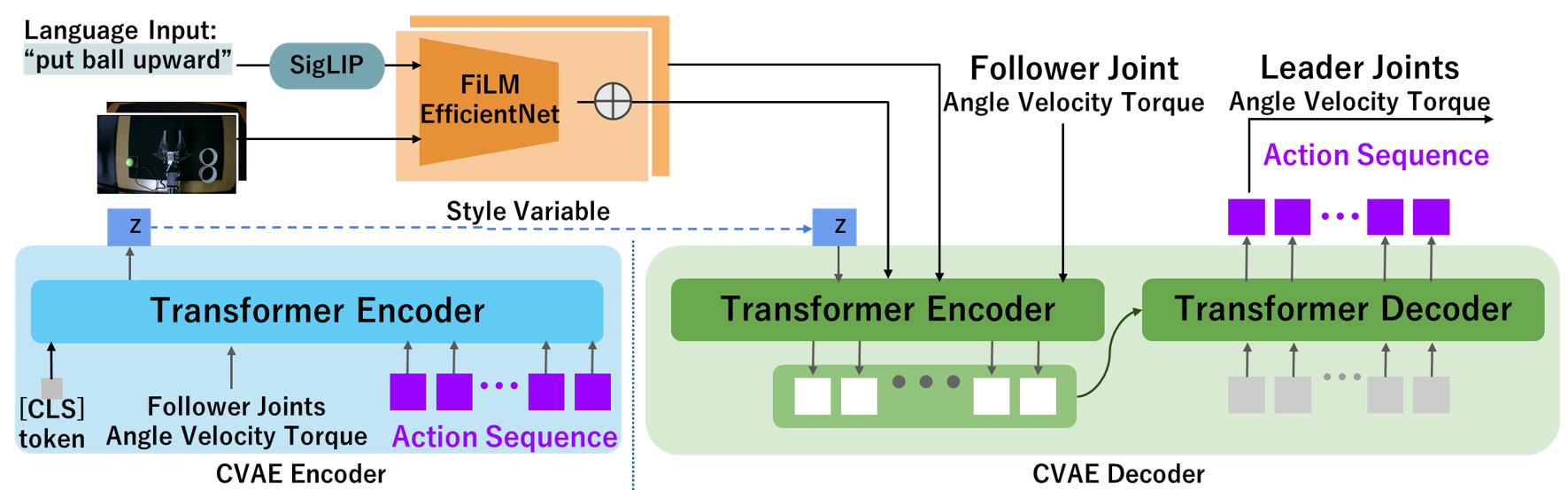
Bi-VLA Model
The Bi-VLA learning model is built upon a Transformer-driven Conditional Variational Autoencoder (CVAE) architecture. In this framework, the model receives the follower robot joints’ angle, velocity, and torque data along with corresponding visual inputs and natural language instructions. Based on this multimodal input, the model outputs sequences of action chunks that specify the predicted joint angles, velocities, and torques of leader robots. Natural language instructions are processed by a dedicated language encoder (LE), which converts the textual commands into fixed-length vector representations.
Data Collection:four-channel bilateral control
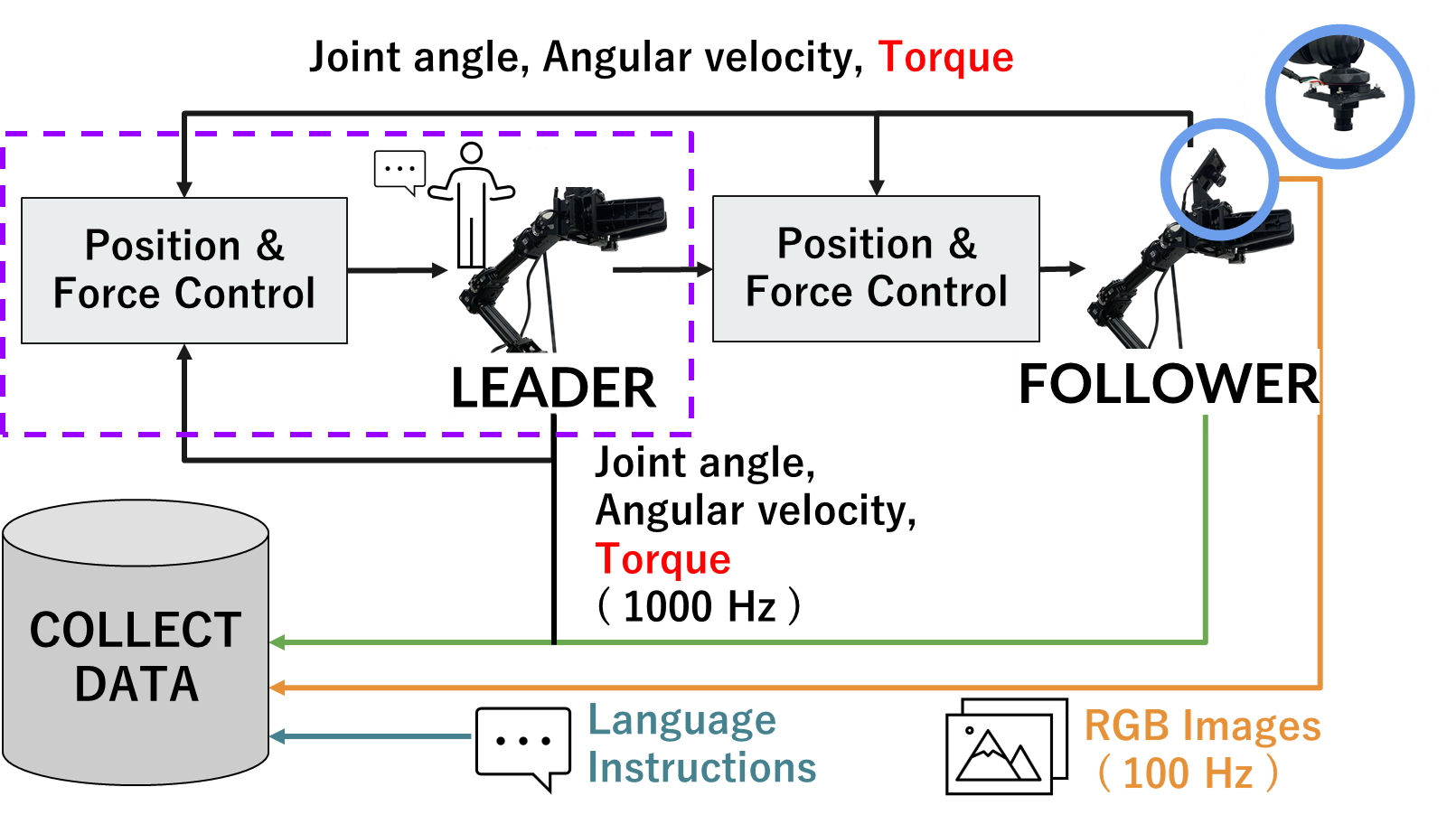
Bi-VLA Data Collection
Inference
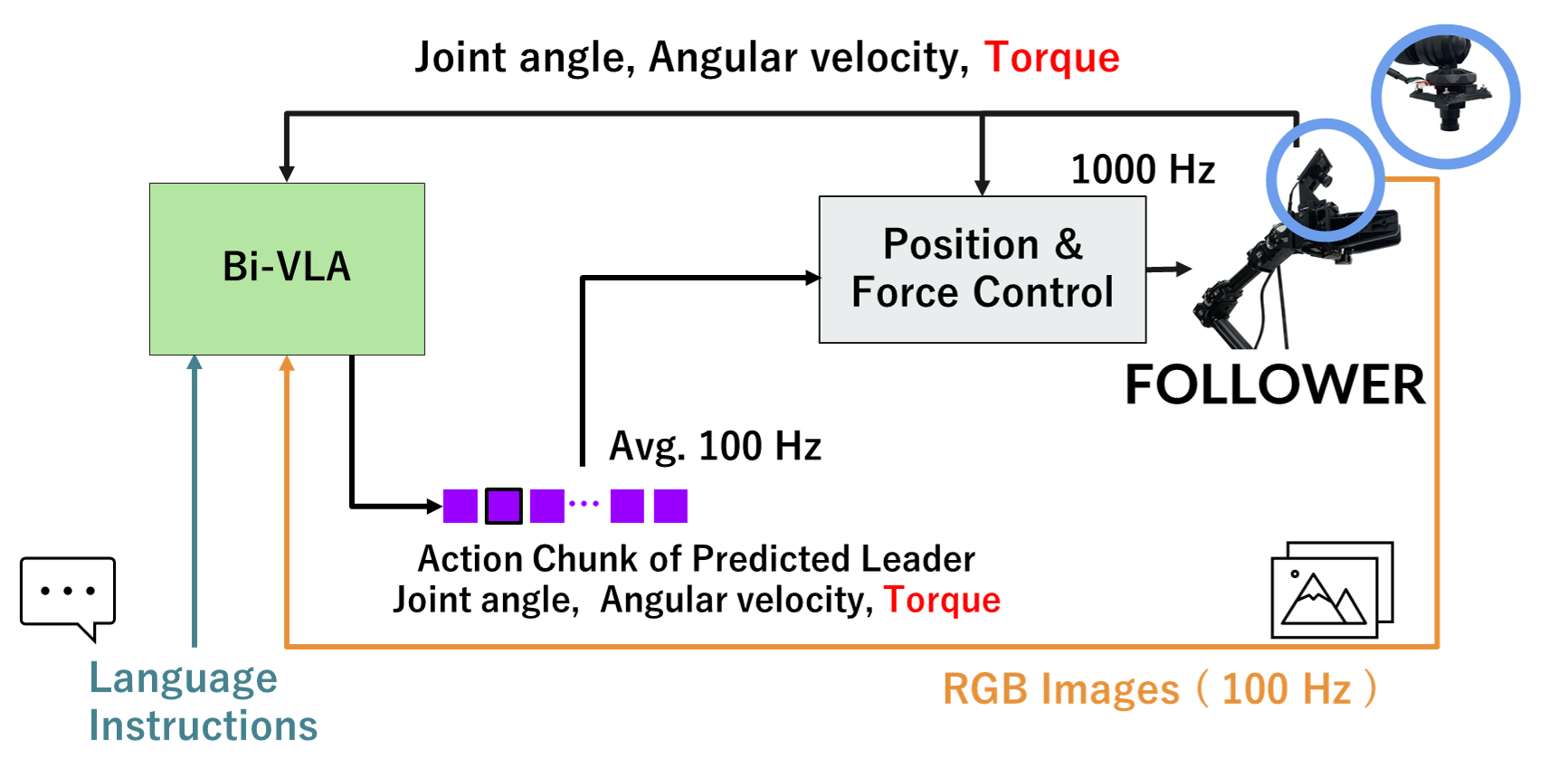
Bi-VLA Inference
Experiments
Overview
We evaluate Bi‑VLA on real‑world pick‑and‑place tasks that require either language‑based disambiguation or vision‑based disambiguation. A human operator provides demonstrations via a leader robot; the policy is executed on a follower robot trained from those demonstrations under bilateral control.

Experimental Environments
Hardware Setup
- Robot: ROBOTIS OpenManipulator‑X (4 revolute joints + gripper = 5 DoF)
- Cameras: Two RGB cameras (overhead and gripper‑mounted), 640×360 @ 100 Hz
- Bilateral control: Leader–follower, four‑channel (position/force exchange)
Task Setup
We design two pick‑and‑place tasks to isolate when language is required vs. when vision alone suffices.
(A) Two‑Target (Language‑Disambiguable) — pick a ball from a fixed source and place it at Up or Down target specified by a language command. Initial visuals are identical, so vision cannot disambiguate the goal.

Data Collection of Two‑Target Task
(B) Two‑Source (Vision‑Disambiguable) — pick the ball from Up or Down source (visually distinct) and place at a fixed target. We additionally test an unlearned 3‑ball environment with a distractor to degrade saliency.

Data Collection of Two‑Source Task
Each setting uses n = 10 evaluation trials per condition. A trial is successful only if Pick → Move → Place complete without unintended drop outside the target area.
Training Setup
Data Collection (Real-Time, 1X)
Model variants
| Model | Training Scope | Language Encoder | Demonstrations |
|---|---|---|---|
| Bi‑ACT | Two‑Target or Two‑Source (separate per model) | — | 6 (3 Up, 3 Down) |
| Bi‑VLA (DistilBERT) | Two‑Target only | DistilBERT | 6 (3 Up, 3 Down) |
| Bi‑VLA (SigLIP) | Two‑Target or Two‑Source (separate per model) | SigLIP | 6 (3 Up, 3 Down) |
| Bi‑VLA (SigLIP‑Mix) | Multi‑task: Two‑Target + Two‑Source (mixed) | SigLIP | 4 raw (1 per condition) → 40 with DABI |
SigLIP‑Mix uses a deliberately reduced data to test cross‑task generalization under limited supervision.
Sensing/Logging: 1000 Hz joint angle/velocity/torque for both leader and follower (5 joints × 3 = 15 per arm; 30‑D combined). RGB images at 100 Hz.
Demonstrations: For each task, 6 demos (3×Up, 3×Down) with paired language:
- Two‑Target: “put ball upward” / “put ball downward”
- Two‑Source: “pick ball upward” / “pick ball downward”
Augmentation: DABI downsampling/augmentation to align 1000 Hz control with 100 Hz images; expands 6 demos → 60.
For Bi-VLA (SigLIP-Mix), we deliberately imposed a reduced data budget to test cross-task generalization. Only four raw demonstrations were collected in total—one for each condition (Target-Up, Target-Down, Source-Up, Source-Down). After DABI augmentation, this produced 40 training data. This design provided a controlled setting to evaluate whether a single multimodal policy could accommodate heterogeneous tasks without task-specific retraining.
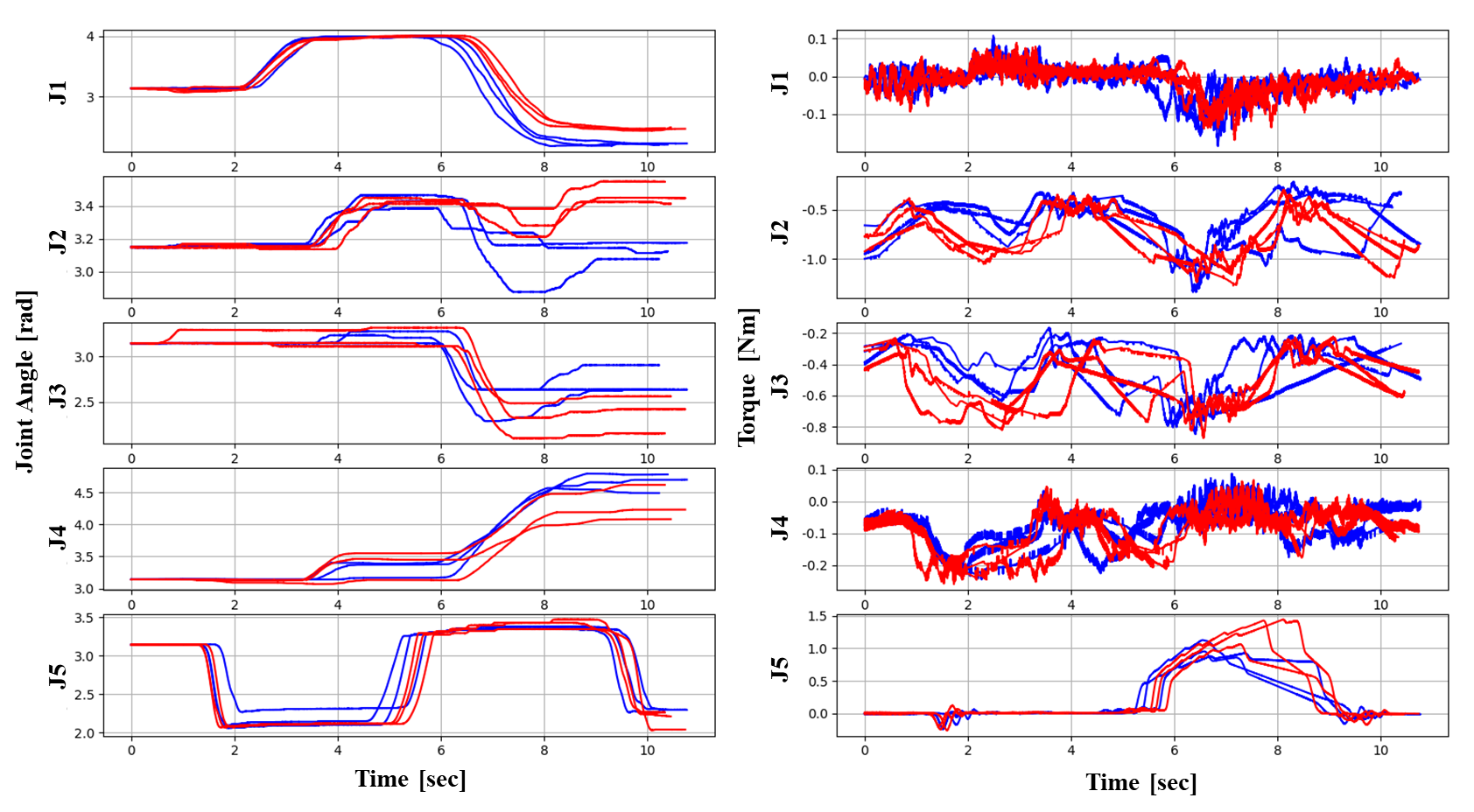
Two‑Target Joint Data (Red: Up, Blue: Down)
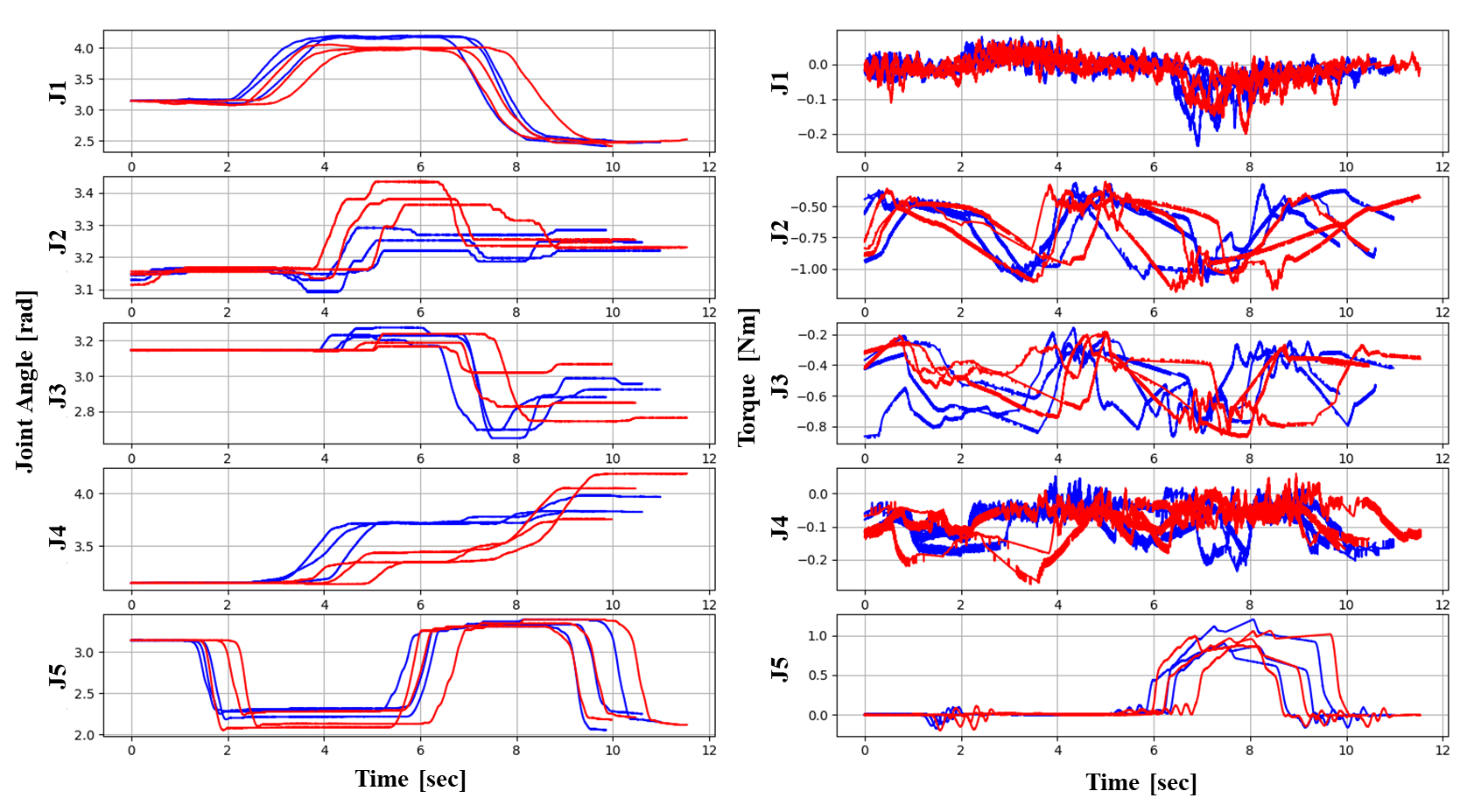
Two‑Source Joint Data (Red: Up, Blue: Down)
Results
Bi-VLA (Real-Time, 1X)
(A) Two‑Target (Language‑Disambiguable)
| Method | Target | Pick | Move | Place | Overall |
|---|---|---|---|---|---|
| Bi‑ACT | Up | 100 | 100 | 100 | 100 |
| Down | 0 | 0 | 0 | 0 | |
| 50 | |||||
| Bi‑VLA (DistilBERT) | Up | 100 | 100 | 100 | 100 |
| Down | 100 | 100 | 20 | 20 | |
| 60 | |||||
| Bi‑VLA (SigLIP) | Up | 80 | 80 | 80 | 80 |
| Down | 100 | 100 | 100 | 100 | |
| 90 | |||||
| Bi‑VLA (SigLIP‑Mix) | Up | 70 | 70 | 70 | 70 |
| Down | 70 | 70 | 70 | 70 | |
| 70 |
Key takeaways: Without language, Bi‑ACT collapses to an Up‑only policy (50%). Language input is indispensable here; SigLIP provides the best grounding and execution (90%), outperforming DistilBERT (60%). SigLIP‑Mix remains balanced across Up/Down under low‑data multi‑task training (70%).
(B) Two‑Source (Vision‑Disambiguable)
| Method | Source | Pick | Move | Place | Overall |
|---|---|---|---|---|---|
| Bi‑ACT | Up | 90 | 90 | 90 | 90 |
| Down | 100 | 100 | 100 | 100 | |
| 95 | |||||
| Bi‑VLA (SigLIP) | Up | 100 | 100 | 100 | 100 |
| Down | 80 | 80 | 80 | 80 | |
| 90 | |||||
| Bi‑VLA (SigLIP‑Mix) | Up | 100 | 100 | 100 | 100 |
| Down | 80 | 80 | 80 | 80 | |
| 90 |
Observation: When vision suffices, adding language offers no extra gain, but also does not hurt. Multi‑task training (SigLIP‑Mix) matches task‑specific SigLIP.
(C) Two‑Source with Unlearned 3‑Ball Distractor
| Method | Source | Pick | Move | Place | Overall |
|---|---|---|---|---|---|
| Bi‑ACT | Up | 100 | 100 | 100 | 100 |
| Down | 0 | 0 | 0 | 0 | |
| 50 | |||||
| Bi‑VLA (SigLIP) | Up | 100 | 100 | 100 | 100 |
| Down | 50 | 50 | 50 | 50 | |
| 75 | |||||
| Bi‑VLA (SigLIP‑Mix) | Up | 90 | 90 | 90 | 90 |
| Down | 70 | 60 | 60 | 60 | |
| 75 |
Generalization: With a visual distractor, language grounding helps avoid biased collapse and sustains substantially higher overall success (75%) than vision‑only (50%).
Summary & Discussion
Across all settings, Bi‑VLA (SigLIP) reliably resolves language‑dependent ambiguity and preserves strong vision‑based control. Bi‑VLA (SigLIP‑Mix) demonstrates multi‑task, low‑data generalization without negative interference between tasks. Together, results show that fusing vision + language within bilateral control yields a single policy capable of flexible task switching and robust performance in real environments.
Citation
@misc{kobayashi2025bivlabilateralcontrolbasedimitation,
title={Bi-VLA: Bilateral Control-Based Imitation Learning via Vision-Language Fusion for Action Generation},
author={Masato Kobayashi and Thanpimon Buamanee},
year={2025},
eprint={2509.18865},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2509.18865},
}
Contact
Masato Kobayashi (Assistant Professor, The University of Osaka, Kobe University, Japan)
- X (Twitter)
- English : https://twitter.com/MeRTcookingEN
- Japanese : https://twitter.com/MeRTcooking
- Linkedin https://www.linkedin.com/in/kobayashi-masato-robot/
 * Corresponding author: Masato Kobayashi
* Corresponding author: Masato Kobayashi