EmoLo: Emotion-Inspired Expressive Locomotion via Single-Policy Reinforcement Learning on Low-Cost Bipedal Robots
The University of Osaka / Kobe University
")
Paper (TBA)

Project page

Video
Legged robots in human-centered settings should combine reliable locomotion with behavior that is expressive and easy to interpret. This paper presents a style-conditioned reinforcement learning framework for Open Duck Mini V2 that generates emotion-inspired walking behavior through three discrete styles—Happy, Neutral, and Sad—using a single shared policy. The policy is trained in simulation with a two-part objective: locomotion terms are inherited from an open-source baseline, while a compact style objective modulates head-pitch posture and motion activity through bounded rewards and a command-dependent gate. Training incorporates sim-to-real considerations such as sensor noise, delay, external pushes, and motor limits, and the controller is exported to ONNX for onboard inference. We evaluate the method in simulation and on hardware under a controlled forward-walking protocol, focusing on trial completion and head-pitch trajectories. The results show successful locomotion with consistent style-dependent head behavior, demonstrating that emotion-inspired expressive modulation can be integrated into a deployable low-cost bipedal controller without multiple policies.

Concept illustration of the three emotion-inspired style conditions (Happy, Neutral, and Sad) across artwork, hardware, and simulation, highlighting head-pitch-related behavior.
Method overview
We learn a single style-conditioned locomotion policy for Open Duck Mini V2 in the joystick task. At each step the policy receives observations and outputs joint torques; an explicit style code (s \in {0,1,2}) selects Neutral, Happy, or Sad. The per-step reward is (r_t = r_t^{\mathrm{loc}} + r_t^{\mathrm{style}}): (r_t^{\mathrm{loc}}) is reused from the open-source locomotion baseline, and (r_t^{\mathrm{style}}) softly shapes head-pitch toward style-specific targets and modulates head activity (with a command gate so style terms do not disturb balance at standstill). After training, the policy is exported to ONNX for onboard inference.
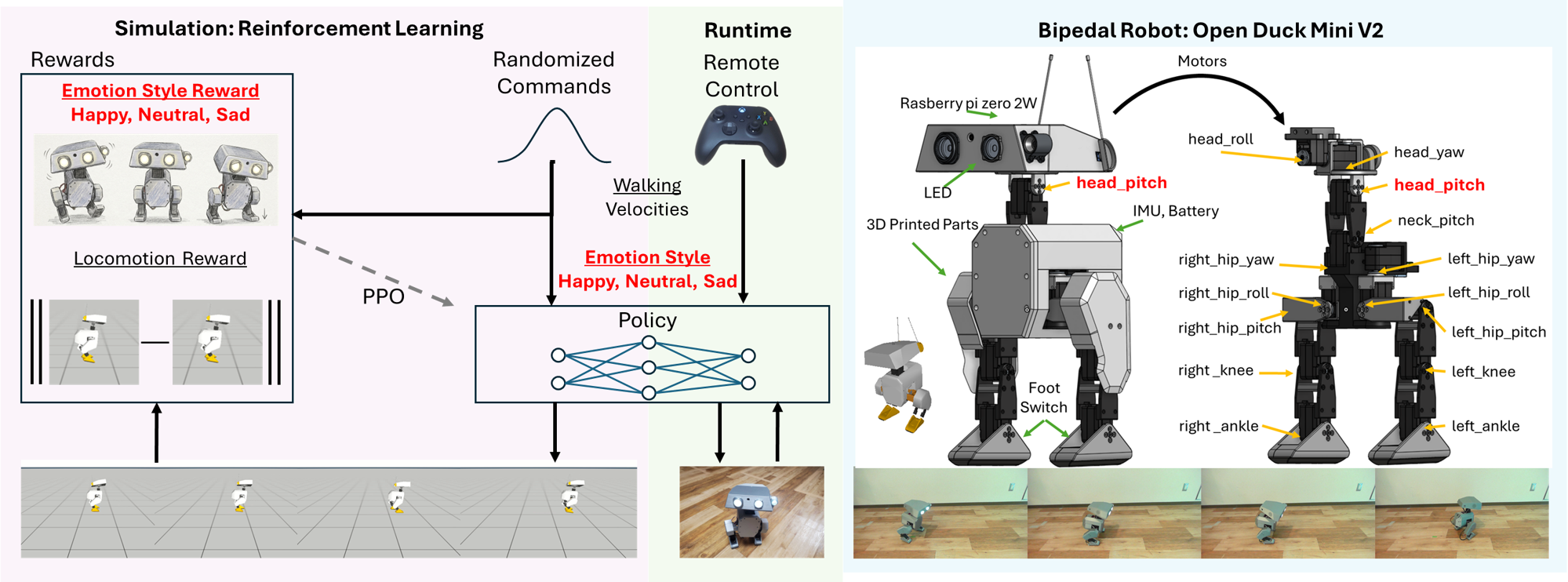
EmoLo system overview.
Robot and deployment

Open Duck Mini V2 and controller (ONNX inference on hardware).
Domain randomization includes sensor noise, action and IMU delay, randomized initial pose, and random external pushes. The real experiment mirrors simulation: (5,\mathrm{s}) of constant forward walking per trial, with style label as the only change across conditions.
Experiments (simulation)
The baseline uses the same architecture but a (101)-dimensional observation (no style one-hot) and reward (r_t^{\mathrm{base}} = r_t^{\mathrm{loc}}) only. The proposed method uses a (104)-dimensional observation and (r_t = r_t^{\mathrm{loc}} + r_t^{\mathrm{style}}). Both policies are trained under identical simulator settings, command ranges, and randomization.
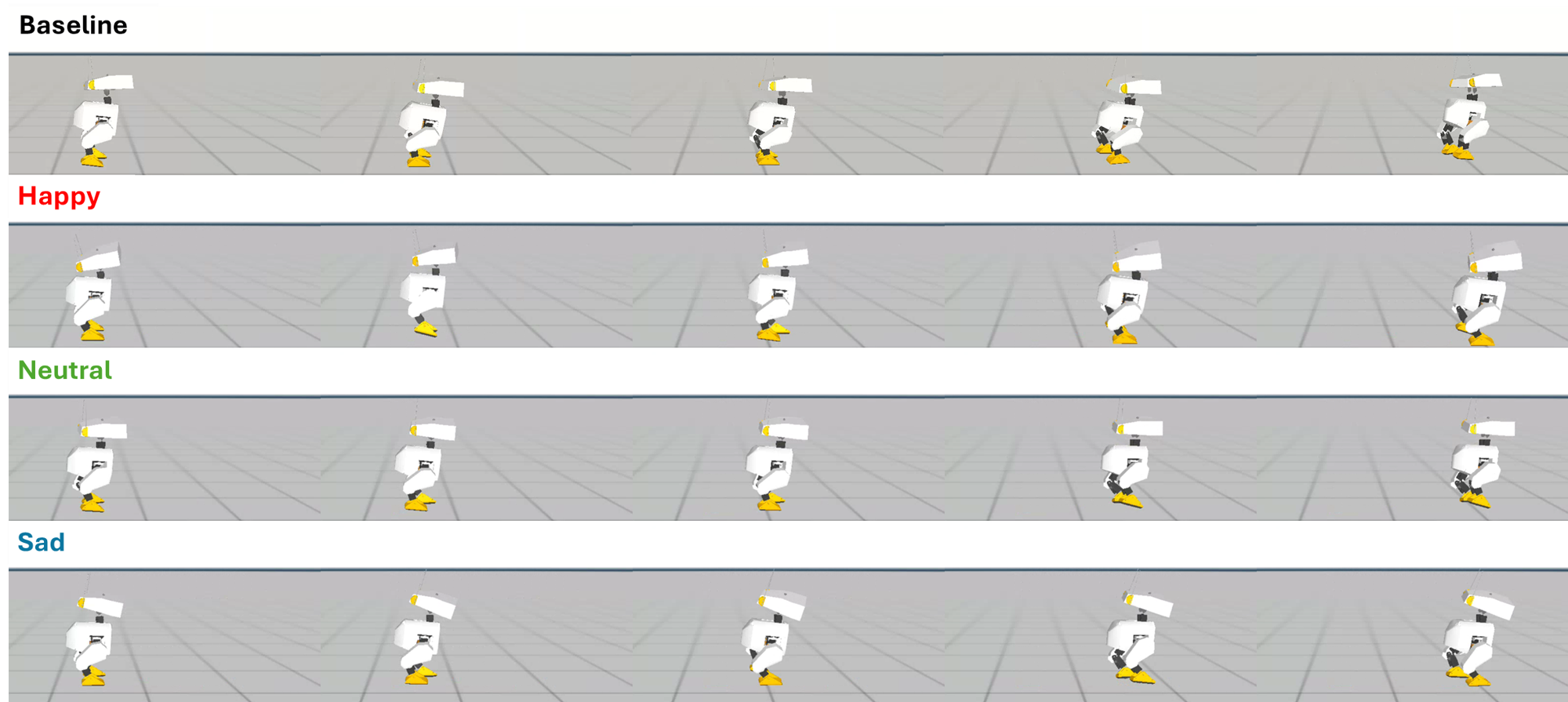
Simulation comparison: baseline vs. proposed style-conditioned policy (Happy, Neutral, Sad).
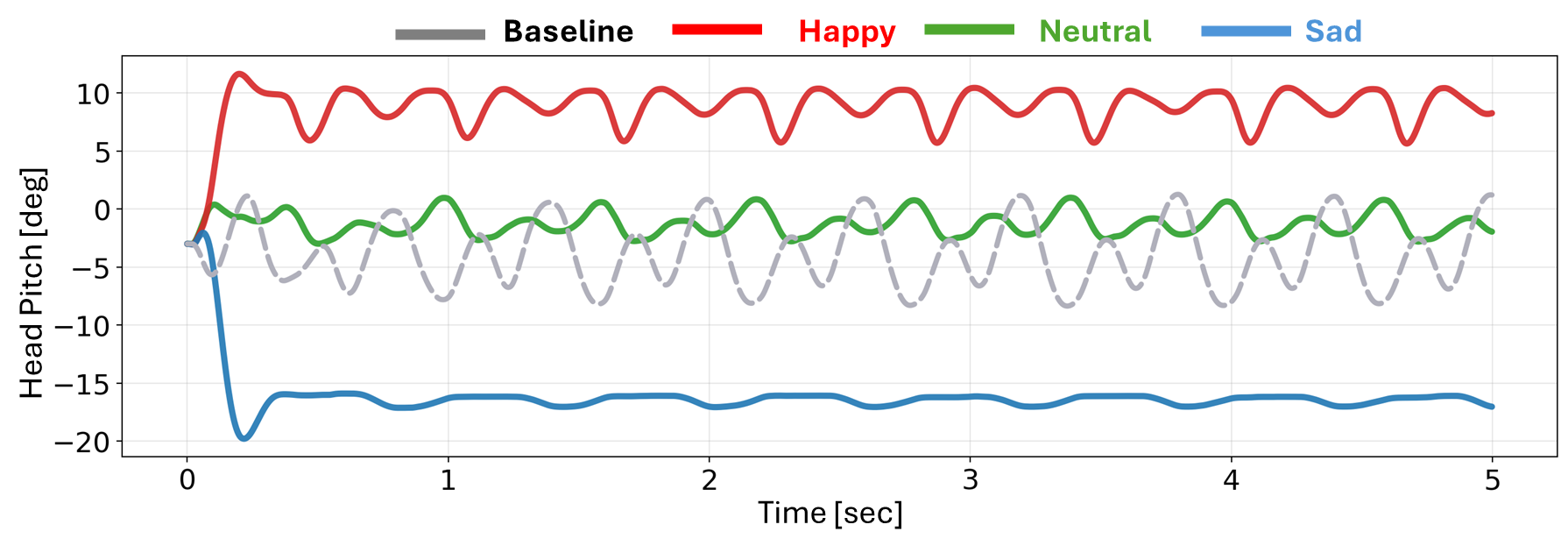
Simulation head-pitch trajectories for the baseline and the three style conditions.
In simulation, both baseline and proposed methods completed the (5,\mathrm{s}) walk without fall. The proposed policy yields clearly separated head-pitch regimes: Happy biases upward with stronger oscillation, Neutral stays near the nominal range, and Sad shifts downward with more subdued motion—consistent with the style reward design.
Experiments (hardware)

Representative hardware snapshots under the three style conditions during the shared forward-walking task.
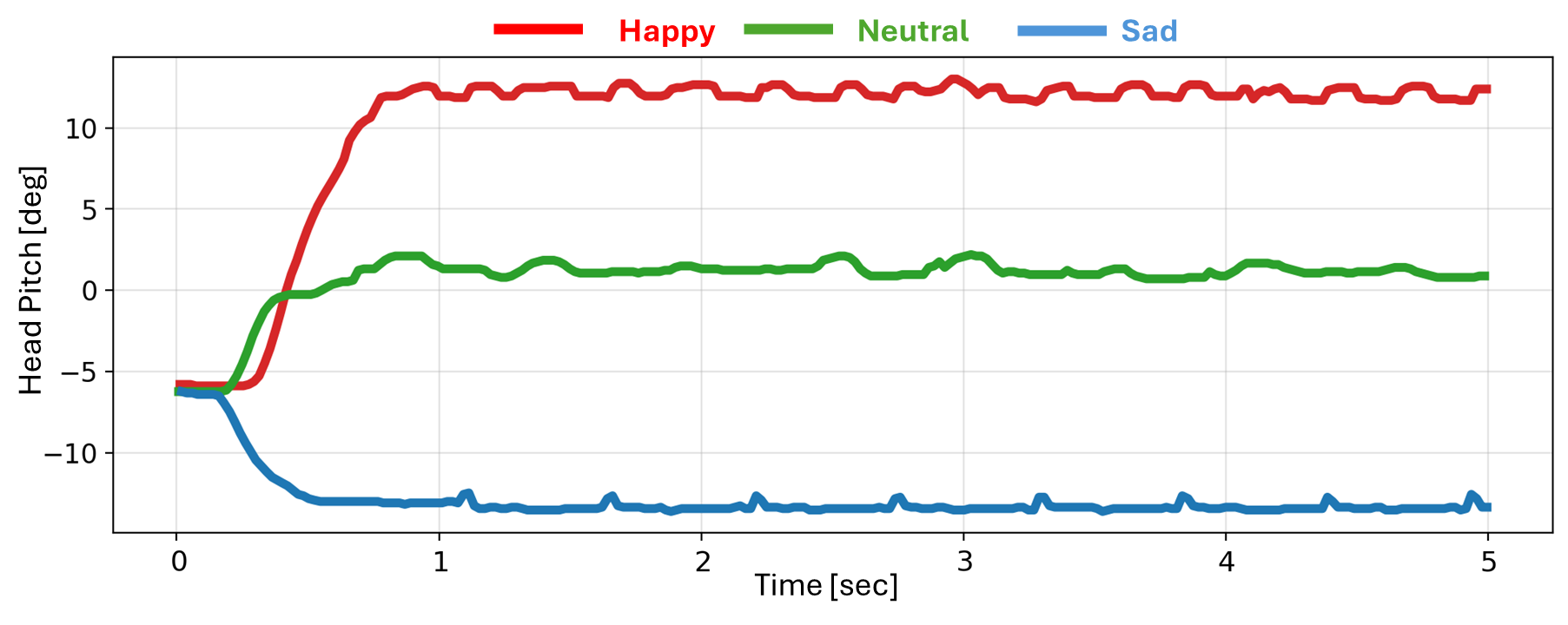
Real-world head-pitch trajectories under the three styles.
The exported ONNX policy ran on the physical robot without on-hardware fine-tuning. Logged head-pitch trajectories preserved the same ordering as in simulation (Happy highest, Neutral intermediate, Sad lowest), supporting direct sim-to-real transfer with lightweight, interpretable style conditioning.
Contributions (summary)
- Emotion-inspired expressive locomotion on a low-cost biped (Open Duck Mini V2), under practical deployment constraints.
- Single-policy, style-conditioned RL: interpretable modulation via reward-level design while preserving the locomotion backbone.
- Practical deployment: ONNX export for onboard inference without multiple policies or external animation modules.
Citation
@misc{kobayashi2026emolo,
title={EmoLo: Emotion-Inspired Expressive Locomotion via Single-Policy Reinforcement Learning on Low-Cost Bipedal Robots},
author={Masato Kobayashi},
year={2026},
url={https://mertcookimg.github.io/emolo/},
}
Contact
Corresponding author
- Masato Kobayashi (Assistant Professor, The University of Osaka, Japan)
X (Twitter)
- English: https://twitter.com/MeRTcookingEN
- Japanese: https://twitter.com/MeRTcooking
LinkedIn: https://www.linkedin.com/in/kobayashi-masato-robot/