MRPoS: Mixed Reality-Based Robot Navigation Interface Using Spatial Pointing and Speech with Large Language Model
The University of Osaka / Kobe University



Recent advancements have made robot navigation more intuitive by transitioning from traditional 2D displays to spatially aware Mixed Reality (MR) systems. However, current MR interfaces often rely on manual “air tap” gestures for goal placement, which can be repetitive and physically demanding, especially for beginners. This paper proposes the Mixed Reality-Based Robot Navigation Interface using Spatial Pointing and Speech (MRPoS). This novel framework replaces complex hand gestures with a natural, multimodal interface combining spatial pointing with Large Language Model (LLM)-based speech interaction. By leveraging both information, the system translates verbal intent into navigation goals visualized by MR technology. Comprehensive experiments comparing MRPoS against conventional gesture-based systems demonstrate that our approach significantly reduces task completion time and workload, providing a more accessible and efficient interface.
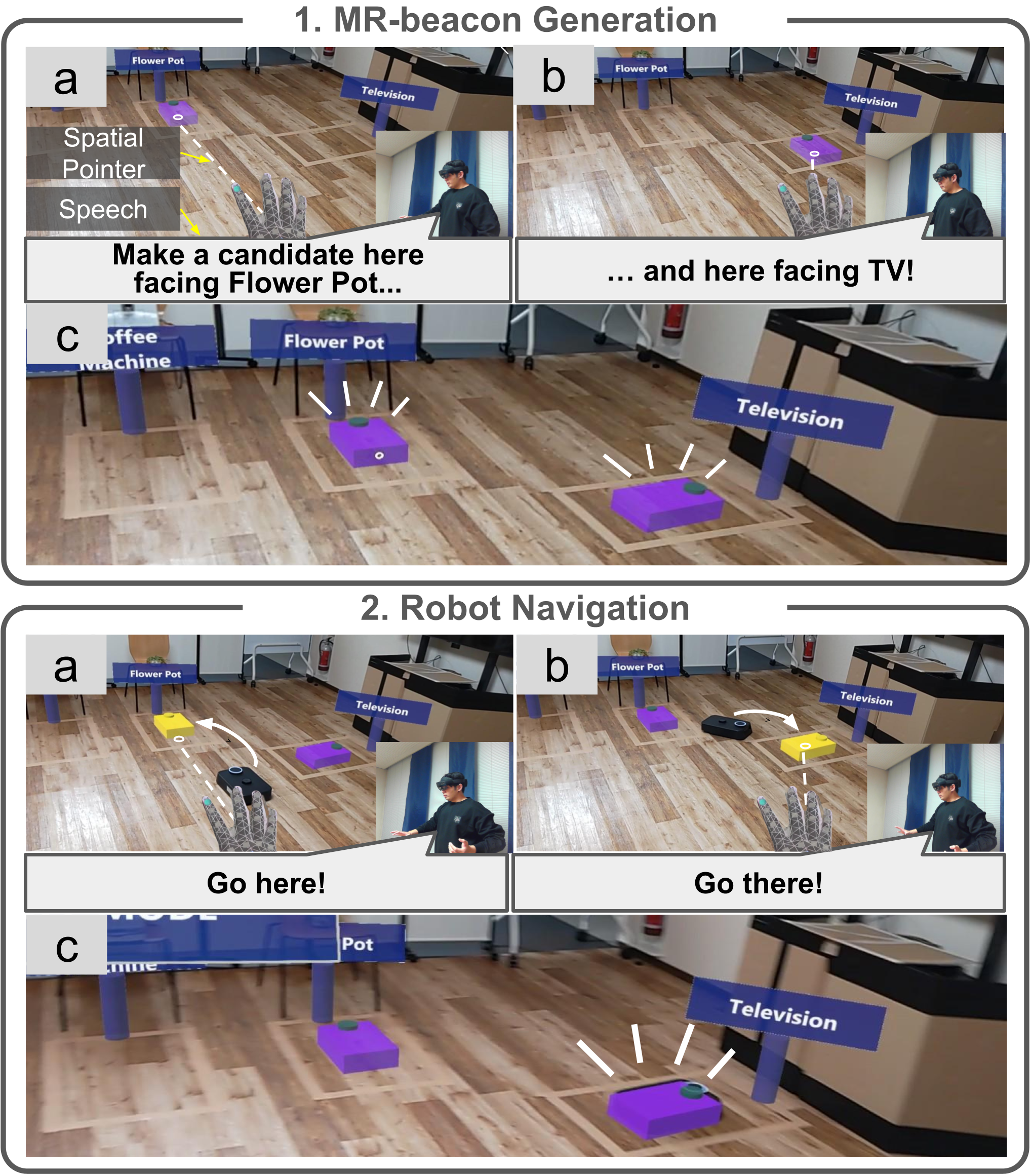
MRPoS Workflow
System Design
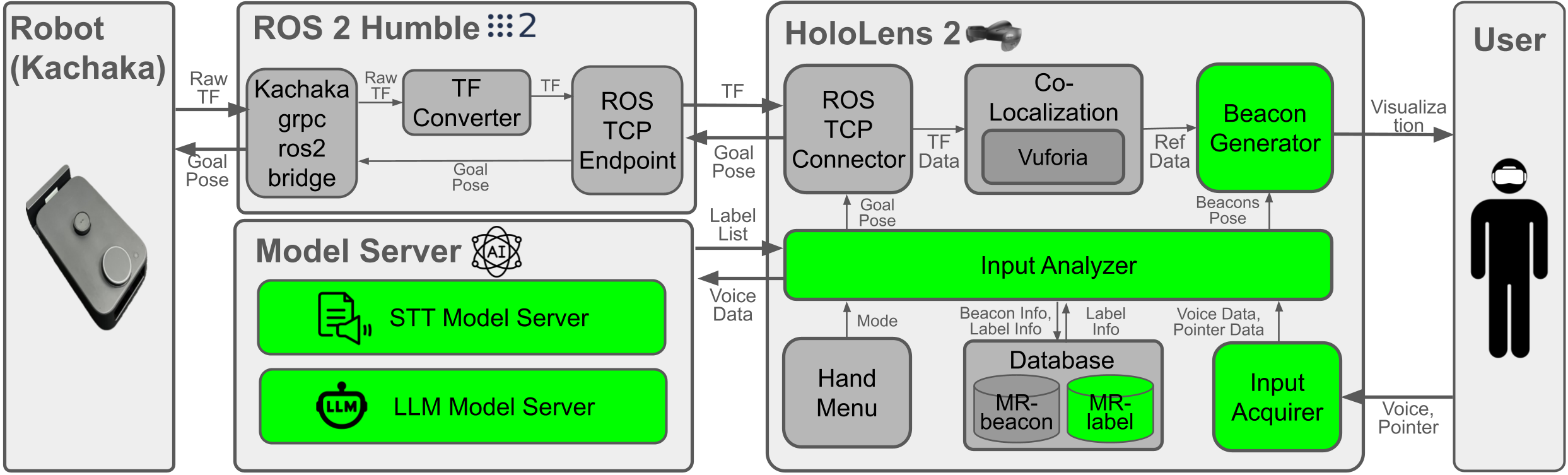
System Design Diagram
The system integrates the Kachaka robot and the HoloLens 2 through a ROS 2 middleware framework. ROS 2 subscribes to the robot’s TF data and sends goal poses, while the HoloLens 2 acts as the primary user interface to acquire, analyze, and visualize MR-beacons. A separate model server hosts the Speech-To-Text (STT) and Large Language Model (LLM) services, communicating with the HoloLens 2 via HTTP. A ROS–TCP connector bridges the HoloLens 2 and ROS 2, enabling bidirectional communication for both robot state and navigation goals.
To access MR-beacon functionalities, the user opens a hand menu via a palm-up gesture. From this menu, they can choose Beacon, Stage, and Calibration options. The Beacon menu exposes six functions: Back, Off, Add, Edit, Go, and Delete. The core interactions—Add, Edit, Go, and Delete—enable users to generate, modify, navigate to, and remove MR-beacons using a combination of spatial pointing and voice commands.
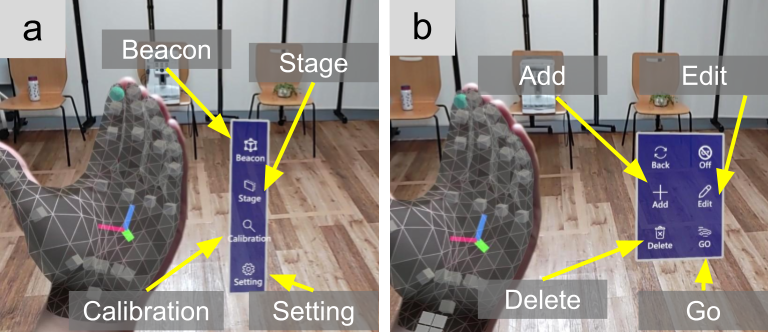
Hand Menu
Add Function
Add Multiple MR-BeaconAdd Single MR-BeaconAdd Single MR-Beacon (Right)
Add Function (Multiple Objects)
The Add function generates MR-beacons directly on the floor plane. When the system enters Add Mode, the user points at the floor to move a semi-transparent candidate MR-beacon in real time. After deciding the location, they issue a voice command that references an MR-label (e.g., “face the coffee machine”) to define the orientation. The system then instantiates a persistent MR-beacon at the calculated pose. By repeating this pointing-and-speech workflow, the user can create multiple target poses in a single continuous interaction.
Edit Function
Edit MR-BeaconEdit MR-Beacon (Back)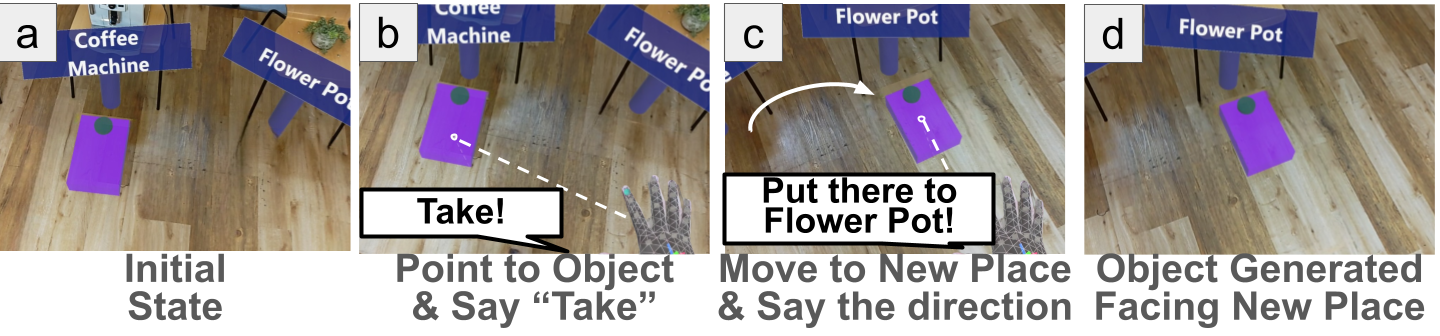
Edit Function
The Edit function modifies the position and rotation of an existing MR-beacon. In Edit Mode, the user selects a beacon by pointing at it and saying “Take,” which attaches the beacon to the pointer. The user then moves the pointer to a new location and issues a voice command specifying the desired orientation toward a particular MR-label. The system updates both the position and orientation of the MR-beacon accordingly.
Go Function
Go!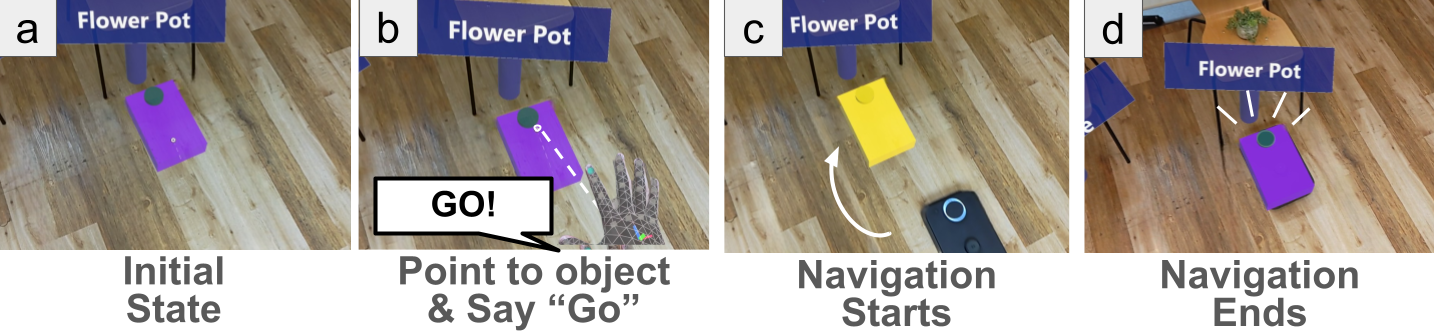
Go Function
The Go function sends the robot to the pose represented by a selected MR-beacon. In Go Mode, the user points at an MR-beacon and issues a “Go” command. The system then sends the corresponding goal pose to the robot through ROS 2, and the robot autonomously navigates to the target.
Delete Function
Delete MR-Beacon
Delete Function
The Delete function removes an MR-beacon from the environment. In Delete Mode, the user points at the target MR-beacon and says “Delete.” The beacon is immediately removed from the scene and its entry in the internal database is updated.
System Implementation

MR-label
MR-labels assign unique semantic names to specific coordinates in the physical environment. Each MR-label stores an ID, a name, and a 3D location, and functions as a persistent directional reference for orientation calculation.
Add MR-LabelEdit MR-LabelDelete MR-Label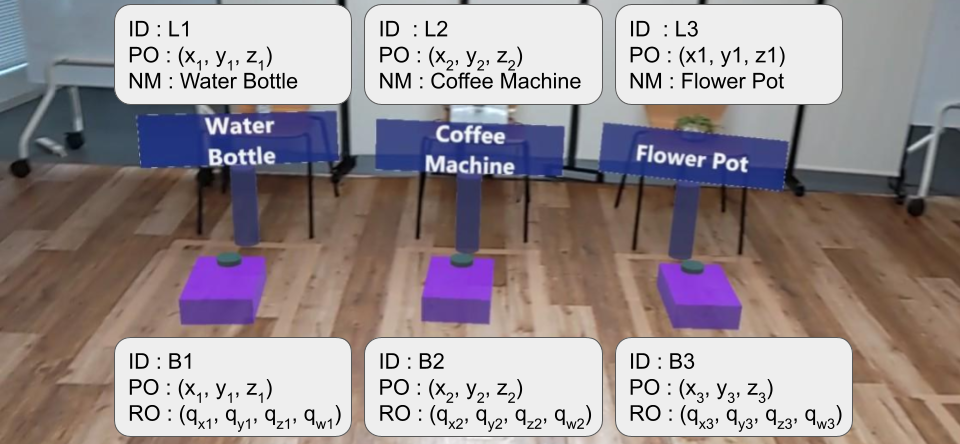
Database
The system maintains separate databases for MR-labels and MR-beacons. MR-label entries store a GUID-based ID, name, and 3D coordinates. MR-beacon entries store an ID, position, and rotation (e.g., quaternion). All data is represented in a common global coordinate frame to simplify pose calculation and co-localization between HoloLens 2 and ROS 2.
To acquire user input, the system employs a Voice Activity Detector (VAD) that detects the onset and end of speech. While the user speaks, the system simultaneously records the audio stream and samples pointer positions on the floor at fixed intervals. After silence is detected, the recorded voice and pointer data are analyzed by the User Input Analyzer.
Inference actions (such as Add Mode) use both modalities. A Voice Analyzer converts audio into text using an STT model (e.g., faster-whisper) and extracts MR-label names with an LLM. A Pointer Analyzer clusters the pointer trajectory into candidate locations using a sequential clustering algorithm. The system then integrates the label list and cluster list to compute a set of MR-beacon poses by orienting each beacon toward the corresponding MR-label location.
Non-inference actions (such as Go and Delete) rely only on pointer information: the system identifies which MR-beacon is intersected by the pointer and executes the corresponding deterministic command.
Experiments
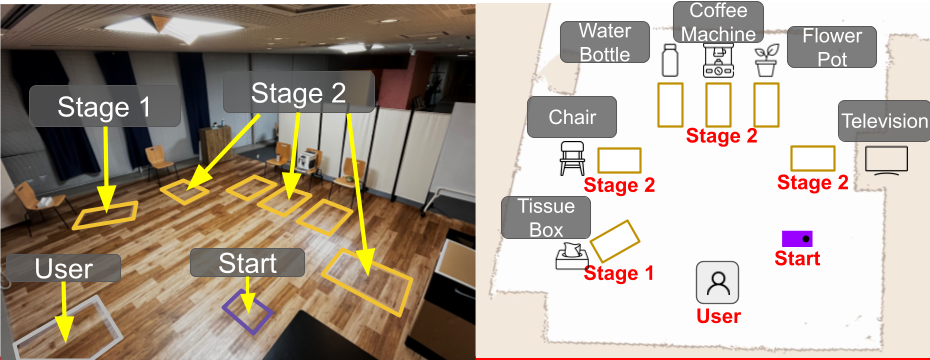
Experiment Environment
To evaluate MRPoS, we conducted user experiments comparing the proposed system with MRNaB as a gesture-based MR baseline. Sixteen participants, most without prior experience in ROS or XR systems, performed navigation tasks in a home-like environment with everyday objects (e.g., tissue box, chair, water bottle, coffee machine, flower pot, TV).
The experiment consisted of two stages. Stage 1 required participants to navigate the robot to a single target (the tissue box) at an oblique angle, emphasizing the difficulty of orientation control. Stage 2 required sequential navigation to three locations (chair, coffee machine, TV), positioned at orthogonal angles, to evaluate multi-destination generation efficiency.

Overall Experiment Flow
Both MRNaB and MRPoS shared a similar procedure: a preparation phase with instructional videos and practice trials, followed by main tasks and post-task questionnaires (SUS and NASA-TLX). For MRPoS, an additional calibration step adjusted voice recognition and clustering parameters (e.g., the distance threshold for clustering pointer points).
Evaluation Indices
Objective metrics included:
- Task time: total time required to generate all MR-beacons.
- Operation count: number of Add and Edit actions required to complete each stage.
- Spatial accuracy: position and rotation errors of each MR-beacon relative to predefined ground truth.
Subjective metrics included:
- System usability: measured by the System Usability Scale (SUS).
- Workload: measured by the NASA Task Load Index (NASA-TLX).
Results
Time Used for MR-beacon Generation

Number of Add/Edit Actions

Location Error

Rotation Error

SUS Score

NASA-TLX Score
Compared with MRNaB, MRPoS reduced the time required to generate MR-beacons, especially in multi-destination tasks, and required fewer Add/Edit operations to complete the same navigation goals. Position and rotation errors remained comparable or improved, indicating that the multimodal interaction did not sacrifice spatial accuracy.
Subjective evaluations showed that MRPoS improved perceived usability (higher SUS scores) and reduced workload (lower NASA-TLX scores), particularly in terms of physical and mental demand. Participants reported that combining pointing and speech felt more natural than repeatedly performing mid-air hand gestures.
These results suggest that MRPoS offers a more efficient and accessible MR robot navigation interface by leveraging multimodal interaction while maintaining reliable spatial grounding.
Citation
@misc{iglesius2026mrposmixedrealitybasedrobot,
title={MRPoS: Mixed Reality-Based Robot Navigation Interface Using Spatial Pointing and Speech with Large Language Model},
author={Eduardo Iglesius and Masato Kobayashi and Yuki Uranishi},
year={2026},
eprint={2603.13313},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2603.13313},
}
Contact
Masato Kobayashi (Assistant Professor, The University of Osaka, Japan)
- X (Twitter)
- English : https://twitter.com/MeRTcookingEN
- Japanese : https://twitter.com/MeRTcooking
- Linkedin https://www.linkedin.com/in/kobayashi-masato-robot/